注意力革命: 微信
· 阅读需 2 分钟


注意力透支,是现代人的新型亚健康。
一个人平均一天要接受六千到一万条广告,无论是有意无意。
这个数量对于 20 年前来说又增长了一倍。
而这些钱可以从广告庄家的兜里看出来,比如腾讯广告从 20 年前的 2 亿到现在的千亿级别。
注意力透支,是现代人的新型亚健康。
一个人平均一天要接受六千到一万条广告,无论是有意无意。
这个数量对于 20 年前来说又增长了一倍。
而这些钱可以从广告庄家的兜里看出来,比如腾讯广告从 20 年前的 2 亿到现在的千亿级别。
一般来说,React 的状态都来源于自身,比如通过 useState 创建的状态。
但是有时候,我们的状态也有来源于别人家,来看 React 官网的经典例子:
监听网络是否在线,如果在线,就显示 ✅ Online,否则显示 ❌ Disconnected:
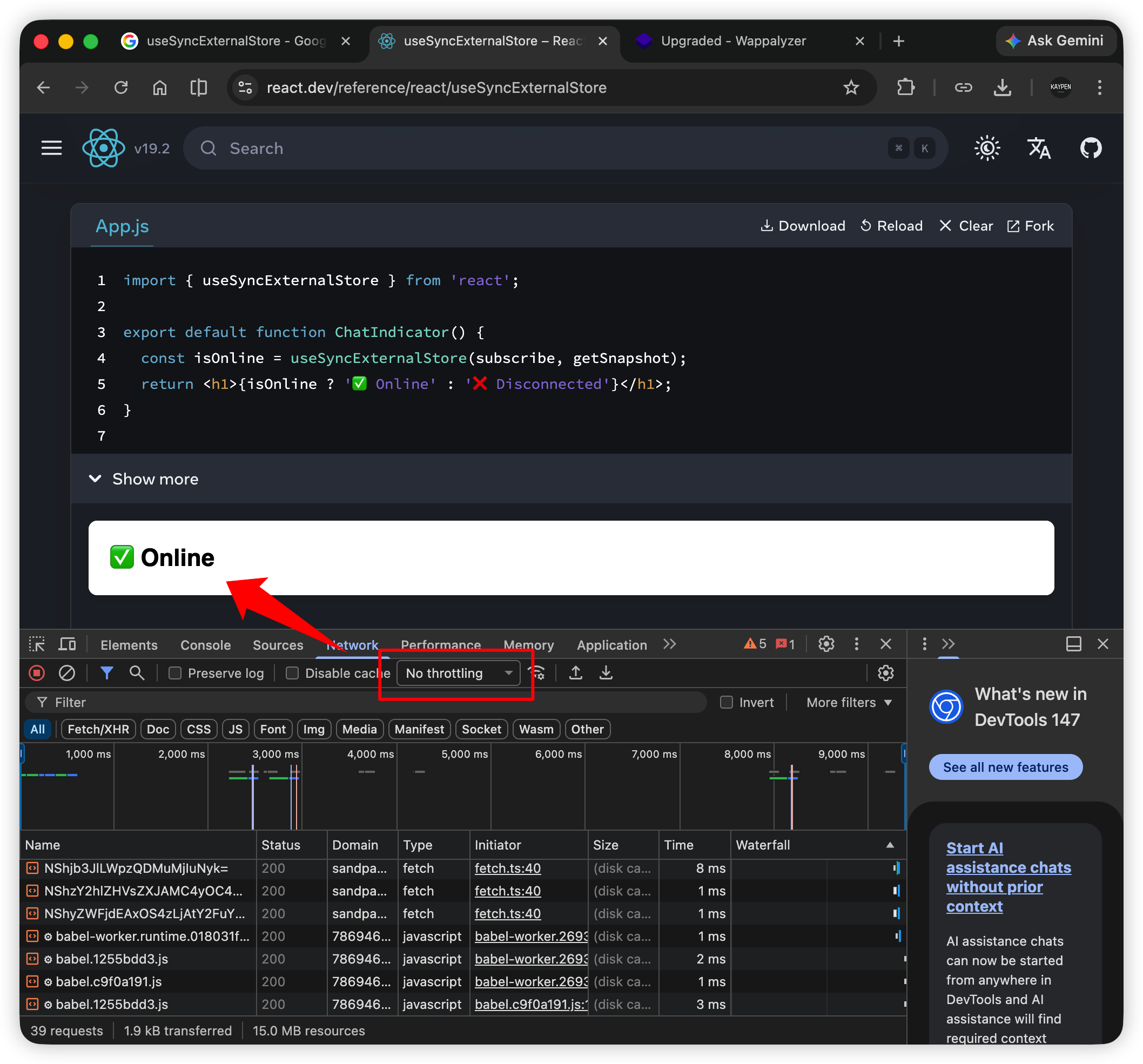
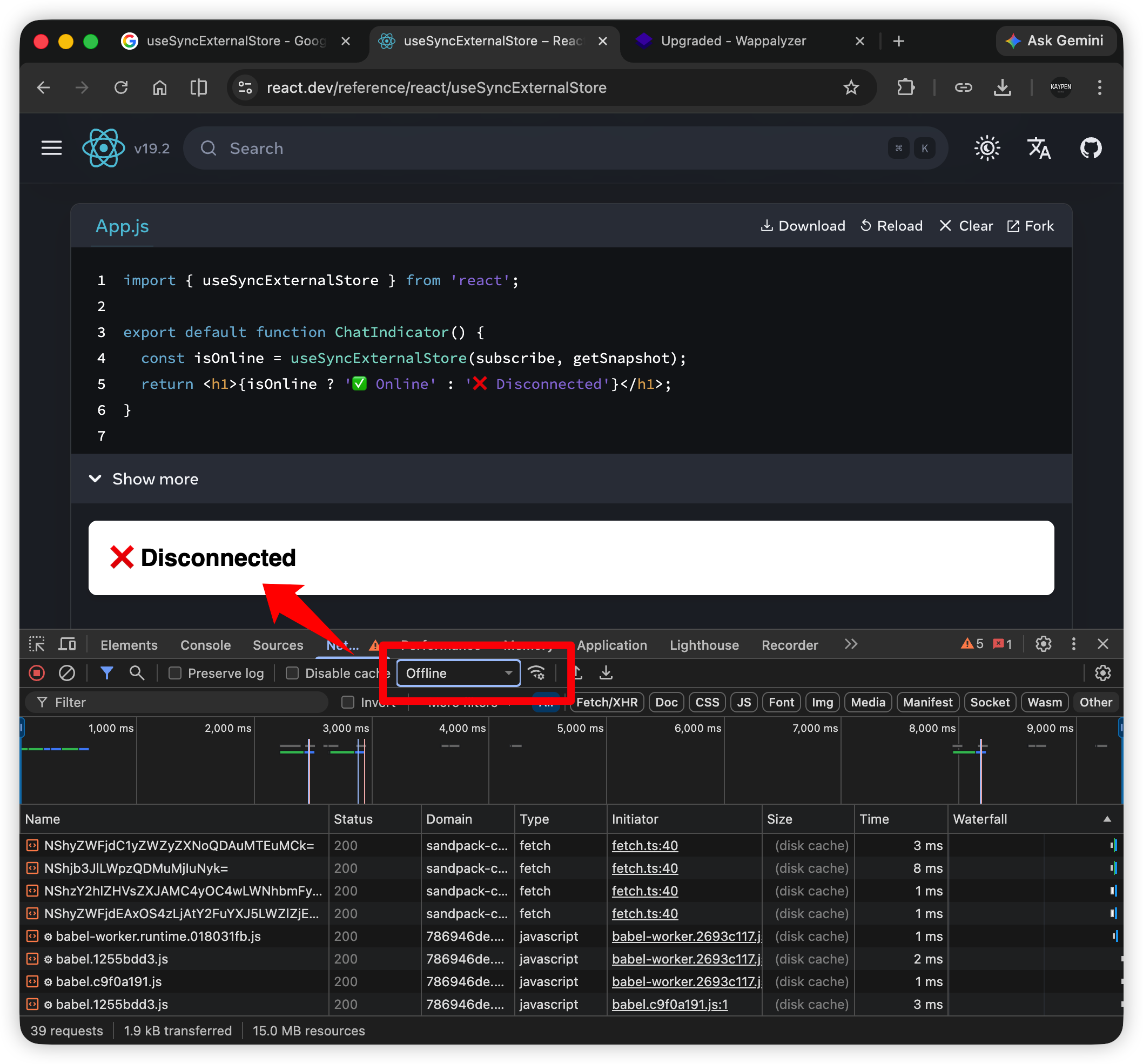
使用 Chrome DevTools > Network 模拟在线、离线状态
这里的在线状态就来自于外部的 navigator.onLine,用 useSyncExternalStore 再合适不过:
import { useSyncExternalStore } from 'react';
export default function ChatIndicator() {
const isOnline = useSyncExternalStore(subscribe, getSnapshot);
return <h1>{isOnline ? '✅ Online' : '❌ Disconnected'}</h1>;
}
function getSnapshot() {
return navigator.onLine;
}
function subscribe(callback) {
window.addEventListener('online', callback);
window.addEventListener('offline', callback);
return () => {
window.removeEventListener('online', callback);
window.removeEventListener('offline', callback);
};
}
可以看到,享用 useSyncExternalStore 的基础配置,一个是订阅函数 subscribe,另一个是获取快照函数 getSnapshot:
const isOnline = useSyncExternalStore(subscribe, getSnapshot);
仔细看订阅函数 subscribe:在函数内部执行逻辑,调用 callback,最后返回一个取消订阅的函数。是不是跟平常用的副作用钩子 useEffect 很类似:
function subscribe(callback) {
window.addEventListener('online', callback);
window.addEventListener('offline', callback);
return () => {
window.removeEventListener('online', callback);
window.removeEventListener('offline', callback);
};
}
这个 callback 需要注意,它是 React 叫的快递小哥,会去调用 getSnapshot,如果拿到新的值,就马上通知商家,重新渲染组件。
在上这个例子中,似乎用 useEffect 也能够完成同样的事情:
import { useState, useEffect } from 'react';
export default function ChatIndicator() {
const [isOnline, setIsOnline] = useState(navigator.onLine);
useEffect(() => {
const handleOnline = () => setIsOnline(true);
const handleOffline = () => setIsOnline(false);
window.addEventListener('online', handleOnline);
window.addEventListener('offline', handleOffline);
return () => {
window.removeEventListener('online', handleOnline);
window.removeEventListener('offline', handleOffline);
};
}, []);
return <h1>{isOnline ? '✅ Online' : '❌ Disconnected'}</h1>;
}
既然 useEffect 可以实现同样的效果,那使用 useSyncExternalStore 是不是脱裤子放屁,多此一举呢?
这就不得不说起 React 的撕裂了,来看一下简单的小组件:

仔细看,在打开的瞬间,这些计数器 Counter 对应的数字都不一样,有 218、219、220,随后统一变成 221。
实际上,这些计数器背后都引用同一个外部数据源。按道理,这些计数器应该始终保持一致。
但是 React 18 新引入的并发渲染机制就是不讲道理。
由于并发,造成了部分组件同步了最新的外部数据,但有些组件落后还没来得及更新。
落后就要挨打,这就是造成了在视觉上,组件被“撕裂”了~。
这就是 useSyncExternalStore 存在的必要性,它会在渲染前调用 getSnapshot 瞟一眼——当前的值最新的吗?如果不是,那就立即丢弃渲染,用新值进行同步、非阻塞的渲染:
@tanstack/react-query (下称 RQ)在 GitHub 上已经累积了 4w+ 的 ⭐,称得上 React 技术栈中必不可少的工具。
它并不像 Zustand 这些通用的状态管理库,而是针对请求这一场景,做了相关的深度优化和功能定制。
RQ 在当前项目已经引入将近两个月,但是使用情况并不多,障碍可能来自于 RQ 的学习曲线和心智认知,所以开展本次 RQ 分享,让团队各位更多地了解 RQ 的能力,进而利用好 RQ,提高开发效率。
目前我们的项目中使用 Axios 作为请求器,而 RQ 并不是用来替代 Axios,而是用来增强 Axios 的。
看一下例子:
// 👉 这是用 Axios 去实现的获取站内信未读总数的接口方法
export function getUnreadNotificationCount(): Promise<number> {
return clientApi.get(URL.GET_UNREAD_NOTIFICATION_COUNT, {
fetchOptions: {
experimental_throw_all_errors: true,
experimental_no_toast_when_error: true,
},
});
}
// 👉 使用 RQ 通过 hook 封装的方式,去增强未读总信接口
import { useQuery } from '@tanstack/react-query';
export const useUnreadNotificationCount = () => {
return useQuery({
queryKey: ['notification', 'unread-count'],
// 👉 RQ 最终调用我们提供给接口方法
queryFn: getUnreadNotificationCount,
});
};
所以 RQ 其实是请求框架无关的工具,它可以和 Axios,GraphQL,或者原生 fetch() 方法等结合使用。
假设我们不使用 RQ,那么正常调用一个接口就是:
import { useState, useEffect } from 'react';
function NotificationBadge() {
// 👉 定义一堆状态
const [count, setCount] = useState(0);
const [isLoading, setIsLoading] = useState(true);
const [error, setError] = useState(null);
useEffect(() => {
// 👉 手动控制各个状态
const fetchCount = async () => {
try {
setIsLoading(true);
const count = await getUnreadNotificationCount();
setCount(count);
setError(null);
} catch (err) {
setError(err);
} finally {
setIsLoading(false);
}
};
fetchCount();
}, []);
if (isLoading) return <div>Loading...</div>;
if (error) return <div>Error loading notifications</div>;
return <div>Unread: {count}</div>;
}
如果这个接口在多个地方使用,我们需要封装为一个自定义 hook:
// 👉 创建自定义 hook
import { useState, useEffect } from 'react';
export function useUnreadNotificationCount() {
const [count, setCount] = useState(0);
const [isLoading, setIsLoading] = useState(true);
const [error, setError] = useState(null);
useEffect(() => {
const fetchCount = async () => {
try {
setIsLoading(true);
const count = await getUnreadNotificationCount();
setCount(count);
setError(null);
} catch (err) {
setError(err);
} finally {
setIsLoading(false);
}
};
fetchCount();
}, []);
return [count, isLoading, error];
}
function NotificationBadge() {
const { count, isLoading, error } = useUnreadNotificationCount();
if (isLoading) return <div>Loading...</div>;
if (error) return <div>Error loading notifications</div>;
return <div>Unread: {count}</div>;
}
使用 RQ 之后:
// 1. 用 RQ 封装自定义 hook
import { useQuery } from '@tanstack/react-query';
export const useUnreadNotificationCount = () => {
return useQuery({
queryKey: ['notification', 'unread-count'],
queryFn: getUnreadNotificationCount,
});
};
// 2. 引用该 hook
function NotificationBadge() {
const { data: count, isLoading, error } = useUnreadNotificationCount();
if (isLoading) return <div>Loading...</div>;
if (error) return <div>Error loading notifications</div>;
return <div>Unread: {count}</div>;
}
RQ 相当于语法糖,简化了自定义 hook 的封装,可以大大减少我们写样板代码。
在我们的通知页中,中间菜单和右侧内容都有标题【点赞】以及未读数【3】,这里的未读数都是通过接口获取:

那么两个地方引用了相同的数据,没有 RQ 的情况下,处理方式有:
状态提升。把请求接口提升到他们的共同的父组件中。
function NotificationPage() {
const [unreadCount, setUnreadCount] = useState(0);
const [isLoading, setIsLoading] = useState(true);
useEffect(() => {
fetchUnreadCount();
}, []);
const fetchUnreadCount = async () => {
try {
setIsLoading(true);
const count = await getUnreadNotificationCount();
setUnreadCount(count);
} catch (err) {
console.error(err);
} finally {
setIsLoading(false);
}
};
return (
<div>
<MiddleMenu unreadCount={unreadCount} />
<RightContent unreadCount={unreadCount} onRefresh={fetchUnreadCount} />
</div>
);
}
Context API:使用 <Context> 组件,跨层级共享数据。
const NotificationContext = createContext();
function NotificationProvider({ children }) {
const [unreadCount, setUnreadCount] = useState(0);
const [isLoading, setIsLoading] = useState(true);
const fetchUnreadCount = async () => {
try {
setIsLoading(true);
const count = await getUnreadNotificationCount();
setUnreadCount(count);
} catch (err) {
console.error(err);
} finally {
setIsLoading(false);
}
};
useEffect(() => {
fetchUnreadCount();
}, []);
return (
<NotificationContext.Provider value={{ unreadCount, isLoading, refetch: fetchUnreadCount }}>
{children}
</NotificationContext.Provider>
);
}
// 使用
function MiddleMenu() {
const { unreadCount, isLoading } = useContext(NotificationContext);
return <div>未读: {unreadCount}</div>;
}
function RightContent() {
const { unreadCount, refetch } = useContext(NotificationContext);
return <div>未读: {unreadCount}</div>;
}
封装 Hook:把请求封装到 hook 中
使用 RQ 之后:
function useUnreadNotificationCount() {
return useQuery({
queryKey: ['notificationCount'],
queryFn: getUnreadNotificationCount,
});
}
function MiddleMenu() {
const { data: unreadCount, refresh } = useUnreadNotificationCount();
return <div>未读: {unreadCount}</div>;
}
function RightContent() {
const { data: unreadCount } = useUnreadNotificationCount();
return <div>未读: {unreadCount}</div>;
}
优点:
✅ 自动去重: 两个组件同时挂载只发 1 次请求(queryKey 相同)
✅ 无需 Provider: 不需要包裹父组件
✅ 组件独立: 每个组件独立使用,不依赖父组件传递
这里提到"两个组件同时挂载只会发起 1 次请求",其原理就是 RQ 会缓存请求的数据。RQ 的很多功能都是基于缓存来操作。
还是通知的例子,当用户打开"点赞"页面,在这里查看消息的时候,【未读数】需要动态更新:

没有 RQ 的情况下,我们需要对这么多个组件做数据联动,方案还是状态提升、Context,当然,还可以通过事件总线(EventEmitter)的方式:
// 定义一个事件总线通用方法:eventBus.js
class EventBus {
constructor() {
this.events = {};
}
on(event, callback) {
if (!this.events[event]) this.events[event] = [];
this.events[event].push(callback);
}
emit(event, data) {
if (this.events[event]) {
this.events[event].forEach(callback => callback(data));
}
}
off(event, callback) {
if (this.events[event]) {
this.events[event] = this.events[event].filter(cb => cb !== callback);
}
}
}
export const eventBus = new EventBus();
// 对于左侧菜单
function LeftMenu() {
const [totalUnreadCount, setTotalUnreadCount] = useState(0);
useEffect(() => {
const fetchCount = async () => {
const count = await getUnreadTotalNotificationCount();
setTotalUnreadCount(count);
};
fetchCount();
// ⚠️ 监听刷新事件
const handleRefresh = () => fetchCount();
eventBus.on('notification:read', handleRefresh);
return () => {
eventBus.off('notification:read', handleRefresh);
};
}, []);
return <div>通知 ({totalUnreadCount})</div>;
}
// 对于中间的菜单
function MiddleMenu() {
const [unreadCount, setUnreadCount] = useState(0);
useEffect(() => {
const fetchCount = async () => {
const count = await getUnreadNotificationCount();
setUnreadCount(count);
};
fetchCount();
// ⚠️ 监听刷新事件
const handleRefresh = () => fetchCount();
eventBus.on('notification:read', handleRefresh);
return () => {
eventBus.off('notification:read', handleRefresh);
};
}, []);
return <div>点赞 ({unreadCount})</div>;
}
// 对于右侧内容
function RightContent() {
const handleMarkAsRead = async (id) => {
await markNotificationAsRead(id);
// ⚠️ 触发刷新事件
eventBus.emit('notification:read');
};
return (
<button onClick={() => handleMarkAsRead(123)}>
标记已读
</button>
);
}
使用 RQ,利用它的 invalidateQueries() 方法可以实现同样的效果:
// 对于左侧菜单
function LeftMenu() {
const { data: unreadTotalCount, refresh } = useQuery({
queryKey: ['totalNotificationCount'],
queryFn: getTotalUnreadNotificationCount,
staleTime: Infinite,
});
return <div>点赞 ({unreadCount})</div>;
}
// 对于中间的菜单
function MiddleMenu() {
const { data: unreadCount } = useQuery({
queryKey: ['notificationCount'],
queryFn: getUnreadNotificationCount,
});
return <div>点赞 ({unreadCount})</div>;
}
// 对于右侧内容
function RightContent() {
const queryClient = useQueryClient();
const { data: unreadCount } = useQuery({
queryKey: ['notificationCount'],
queryFn: getUnreadNotificationCount,
});
const { data: notifications } = useQuery({
queryKey: ['notifications', 'print-and-collect'],
queryFn: () => getNotifications('print-and-collect'),
});
const markAsReadMutation = useMutation({
mutationFn: markNotificationAsRead,
onSuccess: () => {
// ✅ 自动让所有相关查询失效并重新获取
queryClient.invalidateQueries({ queryKey: ['totalNotificationCount'] });
queryClient.invalidateQueries({ queryKey: ['notificationCount'] });
queryClient.invalidateQueries({ queryKey: ['notifications'] });
},
});
return (
<div>
<h2>点赞 (未读: {unreadCount})</h2>
{notifications?.map(n => (
<div key={n.id}>
{n.content}
{!n.isRead && (
<button onClick={() => markAsReadMutation.mutate(n.id)}>
标记已读
</button>
)}
</div>
))}
</div>
);
}
优势:
✅ 零配置自动同步: invalidateQueries 一个方法搞定
✅ 组件完全解耦: <RightMenu>,<MiddleMenu> 和 <RightContent> 互不依赖
✅ 数据一致性: 始终从服务器获取最新数据
✅ 无需手动管理: 不需要回调、Context、事件总线
✅ 乐观更新: 可以先更新 UI,再同步服务器
RQ 底层也是使用发布/订阅(pub/sub)设计模式。
乐观更新对应的是悲观更新,悲观更新也就是比较传统的做法——先请求 API,再更新 UI。
而乐观更新是先更新 UI,再请求 API。
| ✅ 适合场景 | ❌ 不适合场景 |
|---|---|
| 点赞/收藏(高概率成功) | 支付、转账等关键操作 |
| 标记已读/未读 | 复杂的业务逻辑(服务器可能拒绝) |
| 切换开关状态 | 数据结构复杂,难以预测结果 |
| 简单的增删改操作 | 需要服务器计算的数据(如库存扣减) |
| 用户期望即时反馈的操作 |
了解了乐观更新,我们来引用它去优化上一节提到的内容,先更新未读数的 UI,再请求 API:
const markAsReadMutation = useMutation({
mutationFn: markNotificationAsRead,
// ✅ 乐观更新:立即更新 UI,不等待服务器响应
onMutate: async (notificationId) => {
// 取消正在进行的查询
await queryClient.cancelQueries({ queryKey: ['notificationCount'] });
// 保存之前的值(用于回滚)
const previousCount = queryClient.getQueryData(['notificationCount']);
// 立即更新未读数
queryClient.setQueryData(['notificationCount'], (old) => old - 1);
return { previousCount };
},
// ❌ 如果失败,回滚
onError: (err, variables, context) => {
queryClient.setQueryData(['notificationCount'], context.previousCount);
},
// ✅ 无论成功失败,最终都重新获取确保数据一致
onSettled: () => {
queryClient.invalidateQueries({ queryKey: ['notificationCount'] });
},
});
RQ 提供了一个 Devtools,可以作为调试使用,可以提升我们的开发效率。
可以在项目本地开发环境下集成 Devtools,在右下角这个浮动按钮:
TODO
对于 Devtools 来说,比较好用的主要有 Actions 和 Data Explorer,可以手动查看相关数据,也可以触发 RQ 的相关方法:
TODO
中文文档
目前官方文档只有英文,目前有挺多的相关中文文档镜像,比如:
https://tanstack.com.cn/query/latest/docs/framework/react/overview
也可以自行 google "tanstack 中文文档"
沉浸式翻译
一款 web 插件,一键把英文翻译成中文,原汁原味,适合 RQ 原文档学习。
https://chromewebstore.google.com/detail/bpoadfkcbjbfhfodiogcnhhhpibjhbnh?utm_source=item-share-cb
Zread
如果想进一步了解 RQ 的源码或者功能,可以使用 Zread,它已经索引了 RQ 的 GitHub 仓库,并且提供 AI 问答,目前免费: https://zread.ai/TanStack/query
留一个问题
最近,在很多依赖库的类型定义文件中,经常能看到了一个陌生的朋友:satisfies。
相信很多人都和我一样,看完 TypeScript 的相关文档,对这个关键字还是一头浆糊。
satisfies 关键字是 TypeScript 4.9 版本引入的,用于类型断言。
先看一下连接数据库的例子:
type Connection = {}
declare function createConnection(
host: string,
port: string,
reconnect: boolean,
poolSize: number,
): Connection;
这里,我们声明了一个函数 createConnection,它接收四个参数,返回一个 Connection 类型。
接着:
type Config = {
host: string;
port: string | number;
tryReconnect: boolean | (() => boolean);
poolSize?: number;
}
我们又声明了一个 Config 类型,它包含了四个属性:host、port、tryReconnect 和 poolSize。
接下来:
const config: Config = {
host: "localhost",
port: 3000,
tryReconnect: () => true,
}
我们声明了一个 config 变量,它包含这三个属性的值:host、port、tryReconnect。
OK,现在我们来调用 createConnection 函数,并传入 config 参数:
function main() {
const { host, port, tryReconnect, poolSize } = config;
const connection = createConnection(host, port, tryReconnect, poolSize);
}
问题出现了:

这里 port 的类型是 string | number,而 createConnection 函数的参数类型是 string,所以会报错。
为了解决类型定义问题,我们需要加上类型断言的逻辑代码:
function main() {
let { host, port, tryReconnect, poolSize } = config;
if (typeof port === "number") {
port = port.toString();
}
const connection = createConnection(host, port, tryReconnect, poolSize);
}
port 类型正确了,但 tryReconnect 类型错误了:

我们一次性将这些类型修复:
function main() {
let { host, port, tryReconnect, poolSize } = config;
if (typeof port === "number") {
port = port.toString();
}
if (typeof tryReconnect === "function") {
tryReconnect = tryReconnect();
}
if (typeof poolSize === "undefined") {
poolSize = 10;
}
const connection = createConnection(host, port, tryReconnect, poolSize);
}
port、tryReconnect、poolSize 都进行了类型断言,问题解决了。
但是,这样写起来很麻烦,有没有更简单的方法呢?
一种方式是,去掉 config 的类型定义,放飞自我,让它自动被推断:
const config = {
host: "localhost",
port: 3000,
tryReconnect: () => true,
}
这样,我们可以一步到位:
function main() {
let { host, port, tryReconnect } = config;
const connection = createConnection(host, port.toString(), tryReconnect(), 10);
}
但这样放飞类型,会引起另外的错误,比如 config 随便添加一个属性:
const config = {
host: "localhost",
port: 3000,
tryReconnect: () => true,
pool: 10, // 新增了一个属性
}
这样 TypeScript 是一点都不会报错,但却会埋下隐藏炸弹,在代码上线的时候,可能会抓马,为什么 poorSize 不生效?
层层排查,最后才发现原来 poolSize 写错成了 pool。
这个时候,satisfies,千呼万唤始出来:
const config = {
host: "localhost",
port: 3000,
tryReconnect: () => true,
pool: 10,
} satisfies Config;

不负众望,TypeScript 终于报错,告诉我们 pool 属性不存在。
satisfies 关键字为我们提供了一种两全其美的解决方案:
Config)。如果你写了多余的属性(如 pool),或者属性类型不匹配,TypeScript 会立刻报错。这避免了“放飞自我”带来的隐患。: Config) 不同,satisfies 不会改变变量被推断出的原始具体类型。变量 config 的 port 属性类型仍然是 number,tryReconnect 属性类型仍然是 () => boolean。总结来说,satisfies 的核心优势在于:在不丢失(泛化)原始推断类型的前提下,对该值进行类型检查。
这使得我们既能获得编辑器对于具体类型的智能提示和类型推断的好处,又能确保这个值的结构符合我们预先定义好的更宽泛的类型约束,从而写出更安全、更灵活的代码。
哈喽,我是楷鹏。
今天想要分享 Chrome 的一个小技巧,可以一次性打开多个干净独立的 Chrome,让你的开发更丝滑。
开头做个小调查,你平时开发的时候,会使用哪些浏览器呢?
我平时开发的时候,主力就是使用 Chrome。
Chrome 的 DevTools 功能非常强大,满足前端开发调试的绝大数需求。
但是长期来有一个困扰我的问题,就是我的日常使用和开发是耦合在一起的。
比如,我的 Chrome 会装载很多的插件:
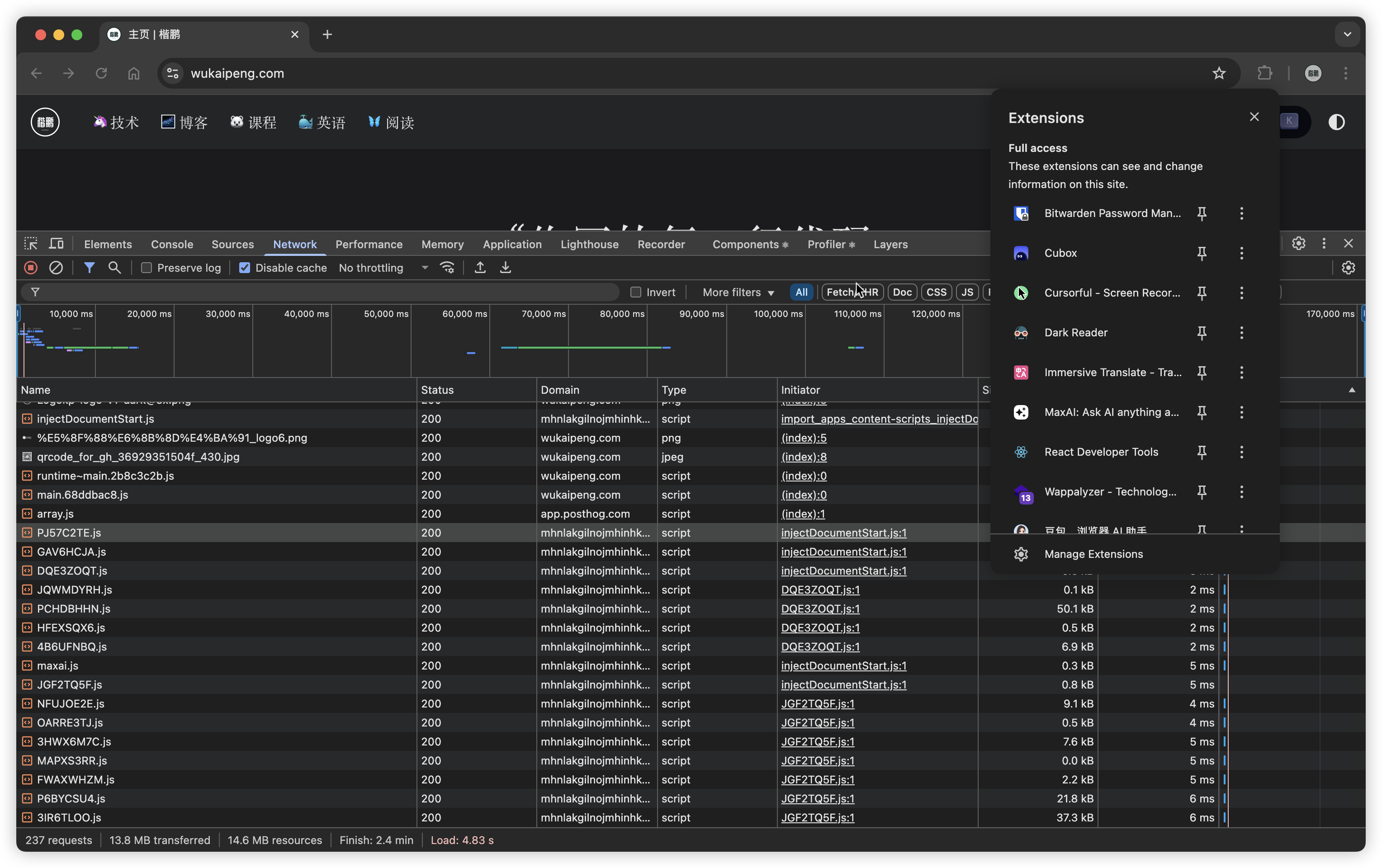
这些插件会影响我的开发,因为他们可能在页面中会插入 HTML 或者 CSS 代码,以及会产生很多额外的请求,干扰我的正常开发调试。
比如下面侧边栏的插件 HTML:
此时的选择,要么是开启无痕窗口,要么是换另外一个浏览器。
这两种方式都不错,但无痕窗口还是使用同一个 Chrome 实例,并且重新打开无痕窗口,所有的状态都会被清空。
另外一种方式是换另外一个浏览器,我曾经尝试过,但是后来又放弃了,换一个浏览器就相当于换一种全新的开发环境,需要重新适应界面、操作习惯等等,真的很别扭。
最近学到了另一种新方式,就是可以通过使用不同的用户数据目录,来创建不同的 Chrome 实例。
运行命令:
/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome --user-data-dir="/tmp/chrome_user_dir_1"
你就可以创建一个全新的 Chrome 实例,并且这个实例的配置、插件、历史记录等都是独立的。
甚至在 Dock 栏,你还可以看到两个 Chrome 图标:

这个新创建的 Chrome 实例,完全可以看作是一个全新的 Chrome 浏览器。
你可以修改主题,来和其他 Chrome 实例区分开来:
或者登录不同的账号等等操作,这是完全属于你的第二 Chrome。
通过运行这条命令,理论上你可以创建无限个 Chrome 实例,只需要修改 --user-data-dir 参数即可,比如:
/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome --user-data-dir="/tmp/chrome_user_dir_2"
/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome --user-data-dir="/tmp/chrome_user_dir_3"
/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome --user-data-dir="/tmp/chrome_user_dir_4"
......
不过平时实际使用的时候,我一般使用两个 Chrome 实例,来回切换,一个用于网站浏览,一个用于开发调试。
在开发调试的时候,每次打开项目再打开新的 Chrome 会有一点点烦躁,所以你可以考虑将这条命令写入到你的前端项目 package.json 的脚本中:
"scripts": {
"dev": "next dev --turbopack",
"open-chrome": "/Applications/Google\\ Chrome.app/Contents/MacOS/Google\\ Chrome --args --user-data-dir=/tmp/ChromeNewProfile http://localhost:3000",
"dev:chrome": "npm run open-chrome && npm run dev"
},
这样你就可以通过 npm run dev:chrome 来打开 Chrome 实例,并且自动运行 next dev 命令。
Windows PowerShell 用户可以使用:
"scripts": {
"dev": "next dev --turbopack",
"open-chrome": "powershell -Command \"Start-Process 'C:\\Program Files\\Google\\Chrome\\Application\\chrome.exe' -ArgumentList '--user-data-dir=D:\\temp\\ChromeNewProfile', 'http://localhost:3000'\"",
"dev:chrome": "npm run open-chrome && npm run dev"
},
如果你希望打开 Chrome 实例的时候,同时打开 localhost:3000 页面来看到页面效果,可以在命令后面直接添加 http://localhost:3000:
{
"scripts": {
"dev": "next dev",
"dev:chrome": "/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome --user-data-dir=\"/tmp/chrome_user_dir_1\" http://localhost:3000 && npm run dev"
}
}
好了,这就是本期的全部内容,如果对你有帮助,欢迎点赞、收藏、转发。
我是楷鹏,我们下期再见。
本期已录制 B 站视频 👉 【Next.js】路由跳转显示进度条
哈喽,我是楷鹏。
先来看一个反面教材。
在 Dify.ai 中,当点击跳转页面之后,会有一段需要等待的时间,然后才会跳转页面。

然而,中间这段时间我并不知道是否跳转成功了,所以我会多点了几下,直到跳转。
这种体验很不好 👎
解决方案很简单,我们来看一下 GitHub 的跳转交互。

可以看到,GitHub 在跳转期间,会显示一个进度条,清晰地告诉用户——"我正在跳转,请稍等"。
那么在 Next.js 中,如何实现这个效果呢?
我们可以借助 BProgress 这个库来实现。

BProgress 是一个轻量级的进度条组件库,支持 Next.js 15+,同时也支持 Remix、Vue 等其他框架。
对于 BProgress 的使用,我做了一个 demo 项目 nextjs-progress-bar-demo,我们可以把这个项目先 clone 下来:
git clone git@github.com:wukaipeng-dev/nextjs-progress-bar-demo.git
然后进入项目目录:
cd nextjs-progress-bar-demo
先安装依赖:
npm install @bprogress/next
启动项目:
npm run dev

可以看到,这是一个简单的 Next.js 项目,包含三个页面:首页、登录页、注册页。
main 分支已经配置好了进度条,我们切换到分支 without-progress-bar-demo:
git checkout without-progress-bar-demo
当前分支下,我们没有配置进度条,所以跳转页面时,不会显示进度条。
接下来我们在根布局 app/layout.tsx 中引入 ProgressProvider:
'use client';
import "./globals.css";
import { ProgressProvider } from '@bprogress/next/app';
export default function RootLayout({
children,
}: Readonly<{
children: React.ReactNode;
}>) {
return (
<html lang="en">
<body>
<ProgressProvider
height="4px"
color="#4c3aed"
options={{ showSpinner: false }}
shallowRouting
>
{children}
</ProgressProvider>
</body>
</html>
);
}
接下来,我们可以看一下,在首页和登录页、登录页和注册页之间跳转,都会显示一个进度条。

ProgressProvider 的参数如下:
height:进度条的高度color:进度条的颜色options:进度条的配置,这里 showSpinner 设置为 false,表示不显示一个动画的加载图标。shallowRouting:是否启用浅层路由,如果开启的话,只改变路由的 query 参数,比如 ?page=1 变成 ?page=2,那么进度条不会重新加载。但是,当我们登录成功之后,再点击跳转,却不会显示进度条。

这是因为,首页和登录页、登录页和注册页之间,是使用 <Link> 组件进行跳转的。
<Link> 组件实际会渲染成 <a>,BProgress 通过给所有 <a> 组件添加点击事件,来显示进度条。
我们可以看下在 DevTools → Elements → <a> → Event Listeners 中,是否添加了点击事件:

但是,当我们登录成功之后,则是使用 router.push 进行跳转的。
BProgress 不会给 router.push 添加点击事件,自然也不会显示进度条。
不用慌,BProgress 为我们提供了 useRouter 方法。
将 Next.js 的 useRouter 替换为 BProgress 提供的 useRouter:
// import { useRouter } from 'next/navigation';
import { useRouter } from '@bprogress/next/app';
然后,正常使用即可:
const router = useRouter();
router.push('/');
这时,你可以看到,在登录成功之后,自动跳转首页时,进度条就能正常显示了。

但如果你的项目已经封装过了自己的 useRouter,那么你可以将封装过的 useRouter 作为参数 customRouter 传入,进行二次封装:
import { useRouter } from '@bprogress/next/app';
import { useRouter as useNextIntlRouter } from '@/i18n/navigation';
export default function Home() {
const router = useRouter({
customRouter: useNextIntlRouter,
});
return (
<button
onClick={() =>
router.push('/about', {
startPosition: 0.3,
locale: 'en',
})
}
>
Go to about page
</button>
);
}
最后,让我们回到 app/layout.tsx,这里我们引入了 ProgressProvider,但却把 app/layout 变成了一个客户端组件,我们来把 ProgressProvider 抽离到其他地方,仍然保持 app/layout 是一个服务端组件。
// app/components/ProgressWrapper.tsx
'use client';
import { ProgressProvider } from '@bprogress/next/app';
interface ProgressWrapperProps {
children: React.ReactNode;
}
export function ProgressWrapper({ children }: ProgressWrapperProps) {
return (
<ProgressProvider
height="4px"
color="#0000ff"
options={{ showSpinner: false }}
shallowRouting
>
{children}
</ProgressProvider>
);
}
在 app/layout.tsx 中,我们引入 ProgressWrapper:
import { ProgressWrapper } from './components/ProgressWrapper';
export default function RootLayout({
children,
}: Readonly<{
children: React.ReactNode;
}>) {
return (
<html lang="en">
<body>
<ProgressWrapper>
{children}
</ProgressWrapper>
</body>
</html>
);
}
好的,不愧是你,完成了一个 Next.js 集成路由跳转显式进度条的封装。
以上就是本期的全部内容,希望对你有所帮助。
感谢观看!👏
作为一个前端 er,工作或者学习中,至少会遇到这么一次,需要区分 Next.js、Nest.js、Nuxt.js 的场景。
我最近就遇到这么一次。
公司有一位新入职的同事,吃饭聊天的时候,听他说之前做过 Next.js 的项目。
由于公司最近的新项目基于 Next.js,我就在想,“太好了,我们的新项目有救了”。
结果,在群聊的时候,他澄清了下,做的是 Nest.js 的项目。
一下子给我立不住了。
作为一个说着普通话的普通程序员,听不清 Next /nekst/ 和 Nest /nest/ 这两个发音,实在是太正常了。
这些框架的起名作者真是聪明。
命名跟批发一样,都是 N__t.js,上一次让我这么犯难的,还是黄金届的“周大福、周六福、周生生、六福珠宝……”
而这场品牌碰瓷,其实主要集中在前端框架爆发的 2016 年左右。
那个时候,前端行业百花齐放,各种框架层出不穷。
在 2016 年 10 月 25 号,Next.js 1.0 发布,首次作为开源项目亮相。
Next.js 基于 React 框架,提供服务端渲染(SSR)和静态站点生成(SSG)功能,以及自动代码拆分、路由系统等特性。
随后的一天,也就是 10 月 26 号,Nuxt.js 发布。
不得不说,Nuxt.js 抄得真快,它基于 Vue.js,整出了另一个 Next.js 翻版。
而 Nest.js 则是在下一年 2017 年的 2 月 26 号发布,它跟 Next.js 和 Nuxt.js 关系就比较远了。
它是纯 Node.js 后端框架,属于是 JavaScript 届的 Spring Boot。
现在这三个框架都发展得很好,除了打铁自身硬之外,是不是更多地得益于“蹭热度”的命名呢?
或许下一次,开发新框架的时候,就叫做 Not.js 吧。
最开始在安装 Node.js 的时候,我们只能通过官网下载安装包,安装指定的一个版本,比如 18.17.1。
但对于不同的项目,我们可能需要使用不同的 Node.js 版本,比如 18.17.1 和 20.17.1。
如果要去切换版本,那就需要卸载旧版本,安装新版本,再切换项目,非常麻烦(痛苦面具)。
于是出现了 Node.js 版本管理器,比如 NVM、Volta 等。
它支持安装指定版本的 Node.js,并且可以自由切换版本。
但是,NVM 存在一些问题,for example,无法根据项目自动切换版本,不支持 Windows 平台(当然,有一个非官方支持的野鸡 nvm-windows 可以使用) 等等。
新一代的 Node.js 版本管理器 Volta 解决了这些问题。
它可以根据项目自动切换 Node.js 版本,并且还支持 Mac、Windows、Linux 三大平台。
Volta 基于 Rust 开发,速度更快,活更好。
根据安装指南,我们在终端中输入以下命令来安装 Volta:
curl -fsSL https://get.volta.sh | bash
安装完成后,打开另一个新终端,输入以下命令来查看当前的 Volta 版本:
volta -v
2.0.2
恭喜你,Volta 安装成功。
接下来,我们就可以使用 Volta 来管理 Node.js 版本了。
在终端中输入以下命令来安装 Node.js:
volta install node
这条命令会安装最新 LTS 版本的 Node.js。
LTS:Long Term Support,长期支持版本。
当然,也可以用艾特符号 @ 安装特定版本的 Node.js,比如:
volta install node@20.17.1
打开一个你正在维护的 Node.js 项目,比如“shit-mountain”,找到 package.json 文件,添加以下内容:
{
//...
"volta": {
"node": "20.17.1"
}
}
当你执行 npm i 时,Volta 会寻找 20.17.1 版本的 Node.js。
如果找不到,Volta 会自动安装 20.17.1 版本的 Node.js,然后再执行 npm i。
这样就确保了项目中使用的 Node.js 版本为 20.17.1。
Volta 还有其他一些特性,比如 Volta 的各种命令,list、uninstall 等等,又比如 Hooks,可以指定下载源,这里就不再展开。
前往 Volta 官网查看更多信息 👉 https://volta.sh
在一些成名的 GitHub 开源项目中,会支持 Vercel 一键部署,比如前两年爆火,如今坐拥 78.7k star 的 NextChat:

那么 Vercel 是什么呢? 它是一个专为前端开发者设计的现代化部署平台,特别适合用于静态网站和前端应用的构建、预览和发布。
So,如果你的开源项目属于静态网站或者前端应用一类的,可以考虑 README.md 上添加 Vercel 一键部署,为你的开源项目增加吸引力。
添加一键部署的方式也很简单,Vercel 提供了一个按钮生成工具:deploy-button

按钮生成器会生成 Markdown、HTML 和 URL 三种方式,可以按需取用
提醒一下,这里的交互会有点奇怪,页面下方是表单输入,比如填写 Git 仓库地址之后,上方 Markdown 链接会自动改变,并且没有成功提醒,这里需要适应一下
这里必填的,只有你的 Git 仓库地址:

其他的还有像是环境变量、默认项目名称、重定向、Demo、集成等,按需填写,最后将生成好的 Markdown 贴到你的开源项目 README.md 上:

整个流程就完成了,非常简单
对于用户侧来说,当他点击部署按钮之后,就会跳转到 Vercel 网站:

这里需要登录 Vercel,同时 Vercel 会要求授予 Git 仓库读写权限,因为 Vercel 会执行对目标仓库的克隆,再以克隆后的仓库为准进行部署:
填写项目名称,点击创建:

接下来就是等待大功告成:

Congratulations!
这里已经能看到网站运行成功之后的预览截图了,也可以点击「Continue to Dashboard」去到控制台,点击 domain 网址,同样能看到网站已经成功部署:

整体回顾来看,Vercel 的部署服务非常丝滑,我甚至都不需要提供框架信息、运行命令等等
So,觉得 Vercel 一键部署的方式不错,那么考虑为你的项目增加一下吧!
如有需要,可查看本文示例项目参考:https://github.com/wukaipeng-dev/ken
Raycast 的 2024 年度统计出来了,这份统计包含了我这一年来用 Raycast 去打开其他应用的情况,看到滴答清单被打开上千次,排列榜首,还是有点小意外
滴答清单英文名:TickTick
今年是尝试并逐渐重度使用滴答清单的一年,一开始,我只想要找一个任务管理的软件,对比过其他很多 todo 软件,滴答清单的免费版本是我个人认为最良心的,大部分功能都涵盖到了
虽然免费很诱人,但还不足以打动我,真正打动的点还是解决了我长久以来的痛点。
在做任务的时候,我用的是番茄工作法,这种方法指的是在 25 分钟(1 个番茄钟)内专注,然后 5 分钟短休息,累计 4 个番茄钟后进行长休息这样的一个周期性节奏去专注
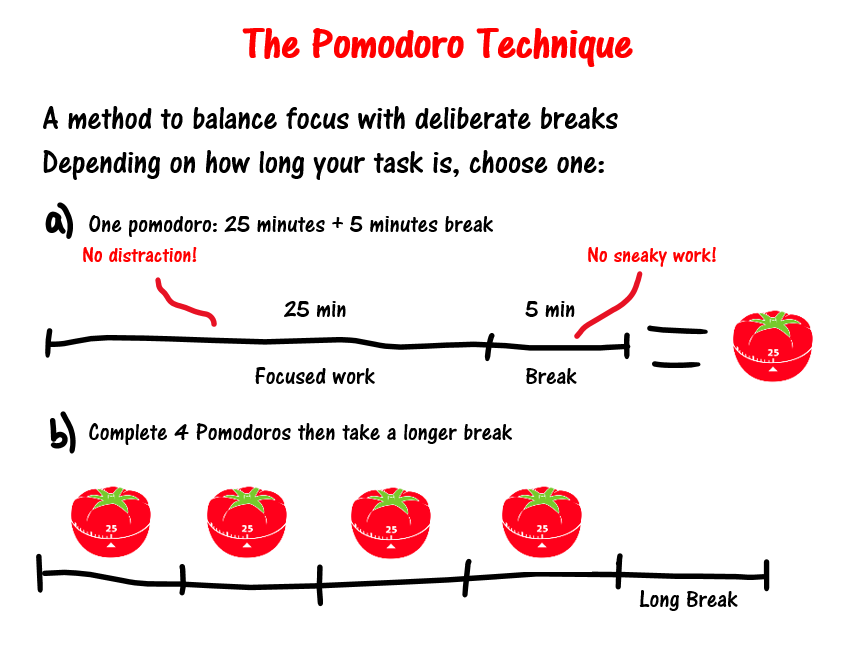
之前我买了一个桌面计时钟,考研党朋友应该很熟悉,类似于下面这种:

这种计时钟既可以正计时,也可以倒计时,也就是做一个 25 分钟的番茄钟倒计时,就这我用了 2 年多,在家里买一个,在公司也买了一个。
它很方便,物理按键,一按就可以开启番茄钟,但它的优点也正是它的缺点。
物理的限制,我不可能随时随地带着一个计时钟,更麻烦的是,一天结束,我不知道每天花了多少番茄钟,不知道什么时候开启番茄钟,不知道番茄钟期间都做了什么任务。
滴答清单在添加任务之后,可以针对这个任务直接开启番茄钟,也可以在番茄钟上去关联对应的任务,同时能做一些额外的笔记,打开统计页面,能清晰地看到每个番茄钟的开始结束

这基本上解决了我的大痛点,另外一个小痒点就是它的通知功能,日常总会忘记开启番茄钟,滴答清单在电脑的菜单栏,可以显式地看到专注的进度:
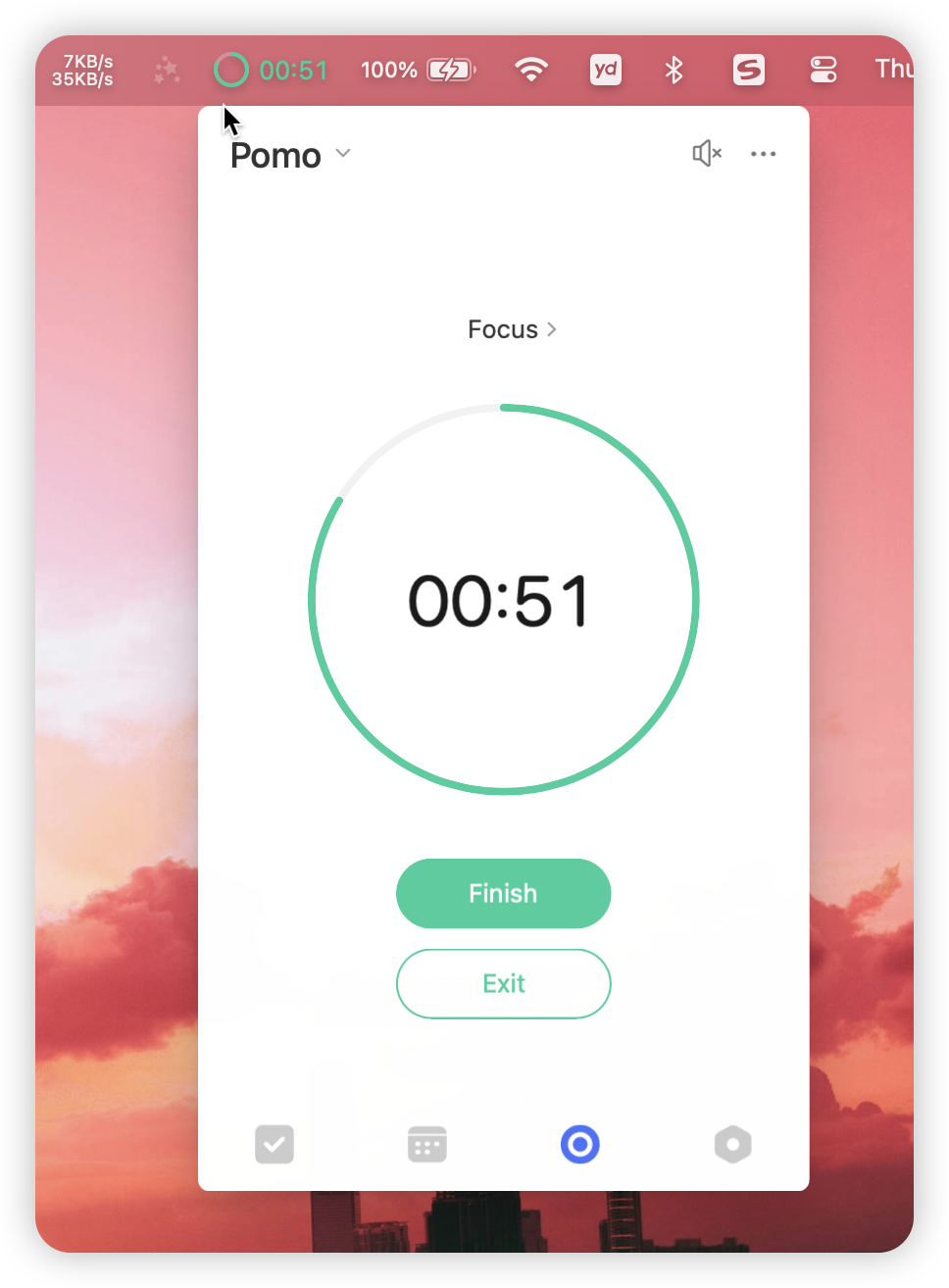
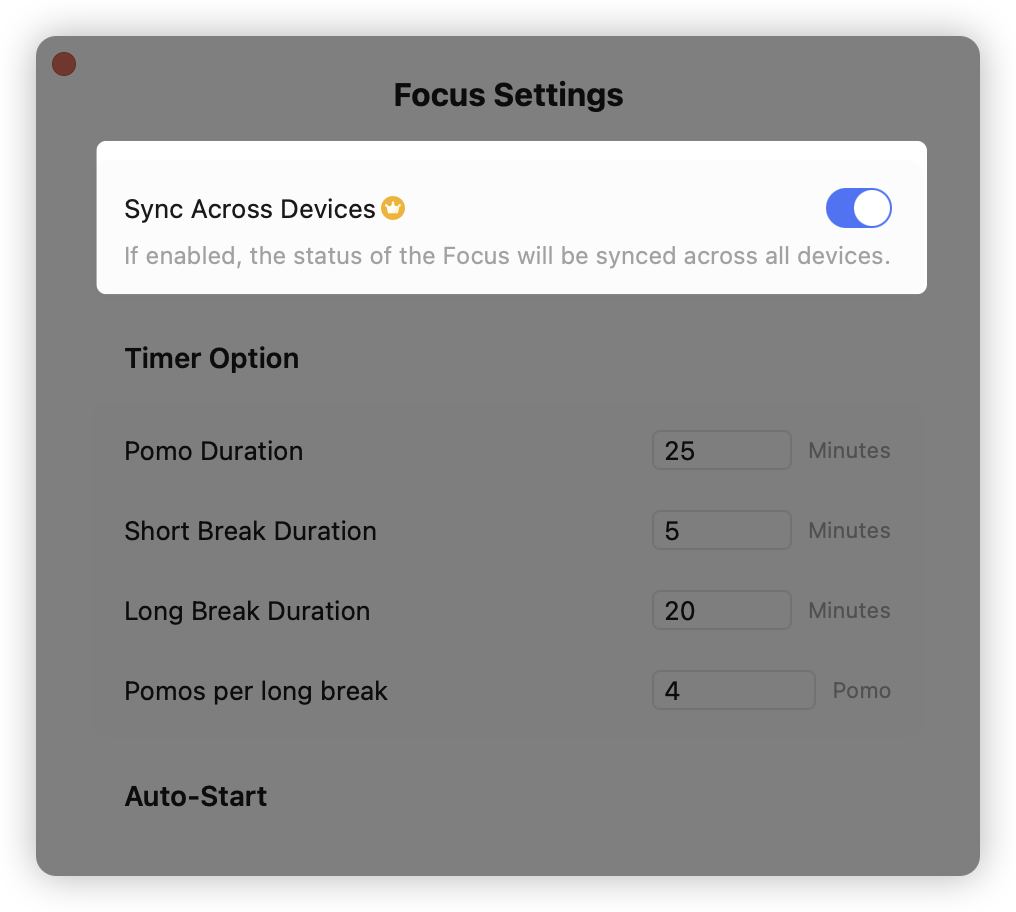
如果开启了跨设备同步,那么手机和电脑都会实时同步当前的专注进度:
让我小小惊喜的是,移动端开启专注模式后,会自动进入沉浸模式,其中除了翻页时钟模式,还有下面这款像素模式,UI 做得特别好看:

滴答清单在解决我的 Big Trouble 之后,我开始慢慢上手其他功能。
对于核心功能——任务管理,第一个提的点是对任务的分类,我相信很多人的分类都比较杂乱,今天加一个「读书」的类目,明天加一个「项目管理」的类目,而且类目一旦多了起来就难以管理了
这里我推荐一个非常实用的分类方式,那就是按照「角色」划分
在公司里,角色就是「员工」,在学校里,角色就是「学生」,在跑道上,角色就是「运动员」,在任意的社会关系中,每个人都是不同的角色。
在我个人的滴答任务分类中,会有管理员(Admin)、员工(Worker)、开发者(Dev)、Friend(朋友)、读书人(Reader)等等角色
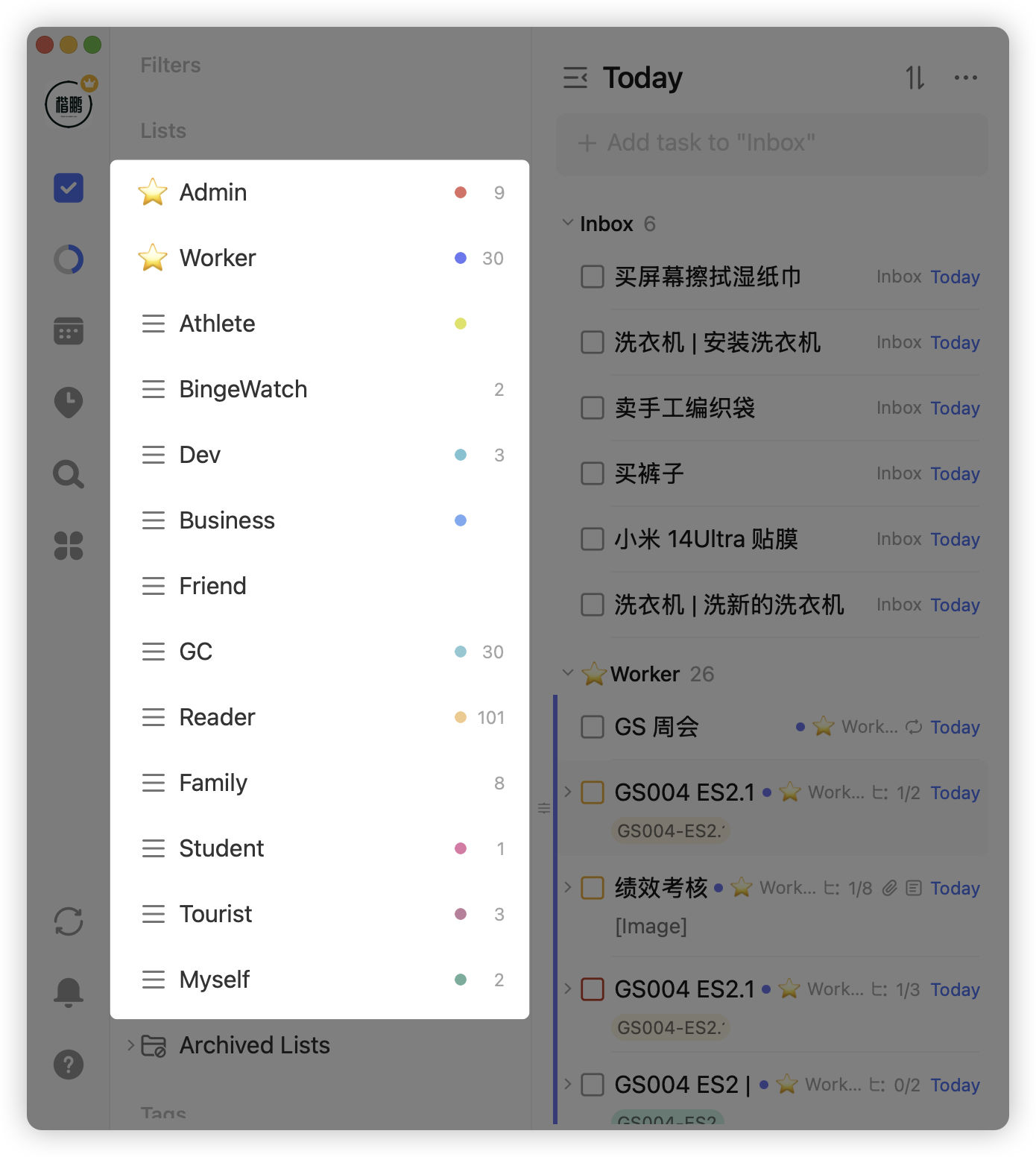
这种划分方法非常稳定,我的任务分类一旦划分后,几乎没有大的改动,它还足够灵活,比如喜当爹了,那就加一个「父亲」角色,买奶粉、换尿布的任务都怼在这个角色上
按照角色划分,几乎囊括了所有的事情,但对于某些角色来说,它需要横向扩展,比如作为员工,需要做项目 a、项目 b 、项目 c 等等,那么可以使用标签,为任务打上对应标签,也就能够把角色下不同的任务类型区分开来:
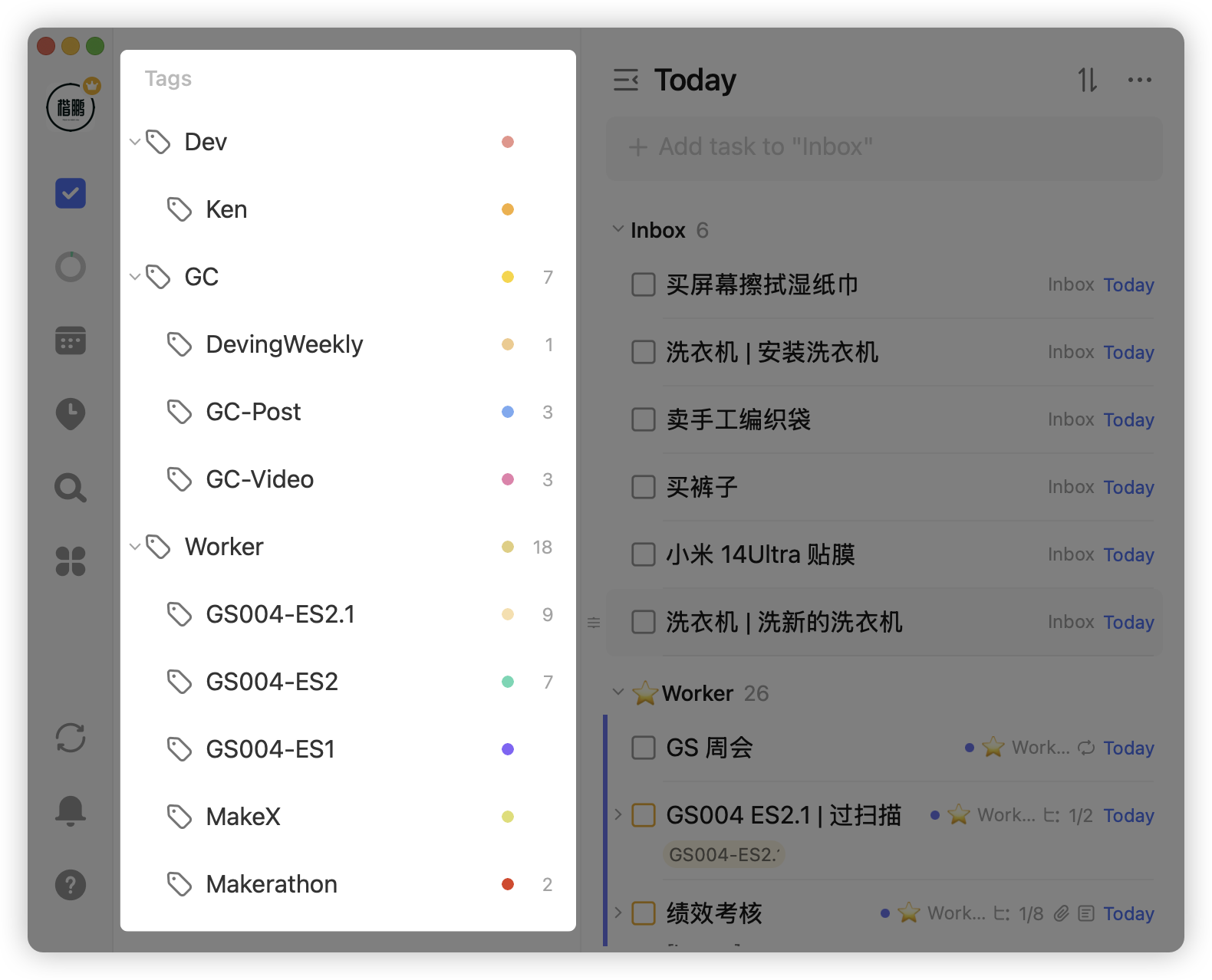
通过角色划分 + 标签系统,基本可以建立一个有序稳定的分类体系了
第二点是任务处理方面,滴答清单藏了很多小心思,比如可以设置预估任务使用的番茄钟数量:
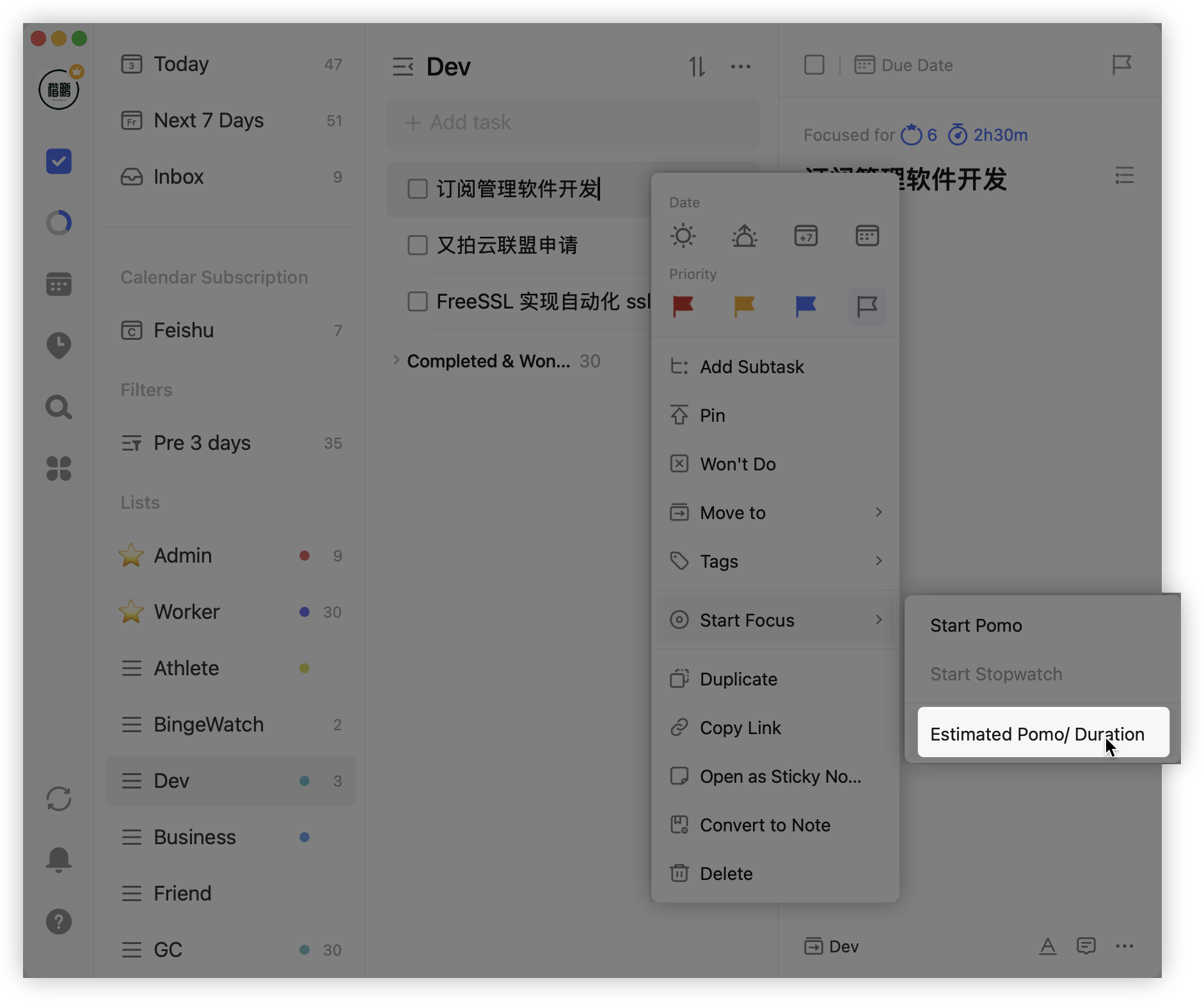
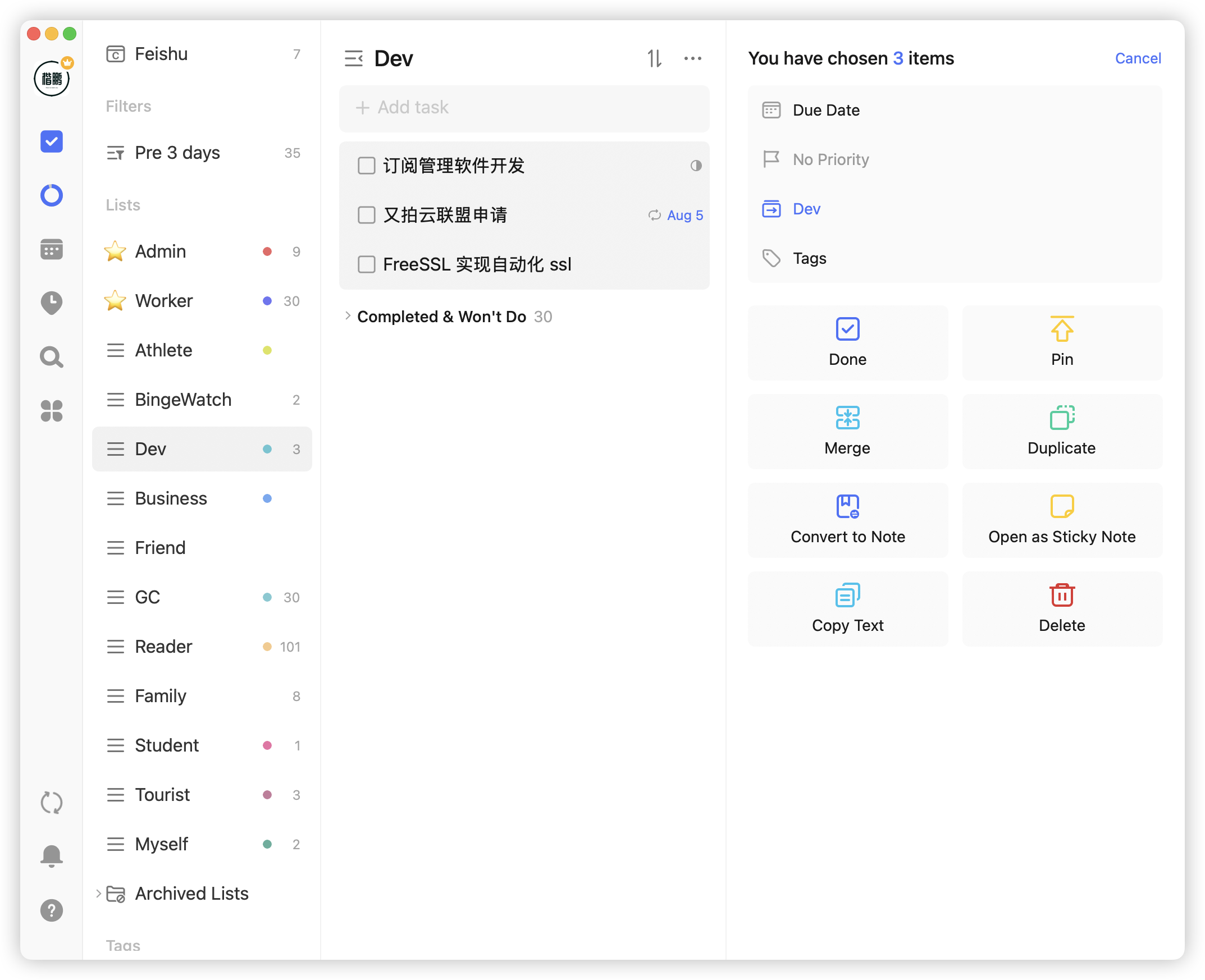
还比如可以设置任务进度百分比:
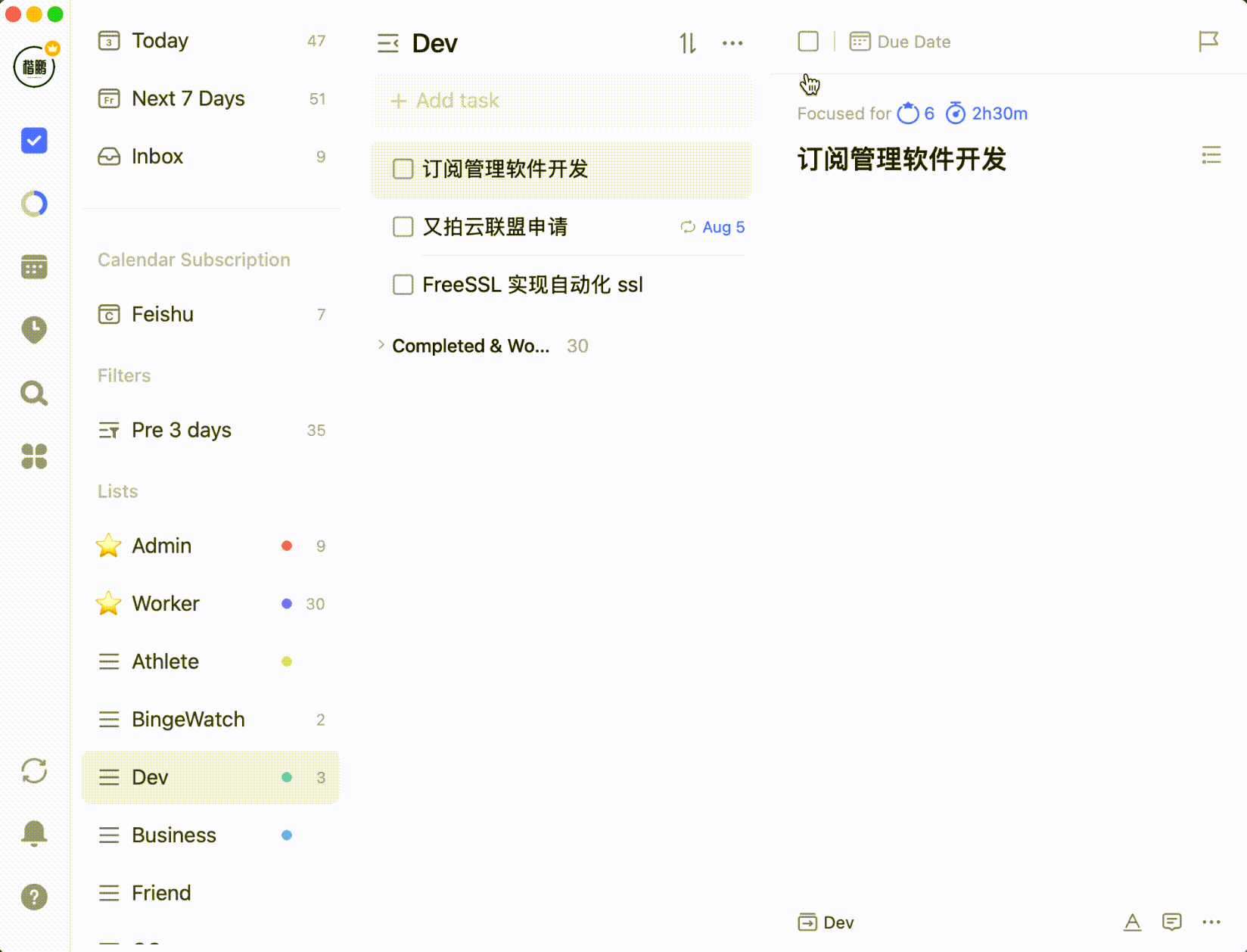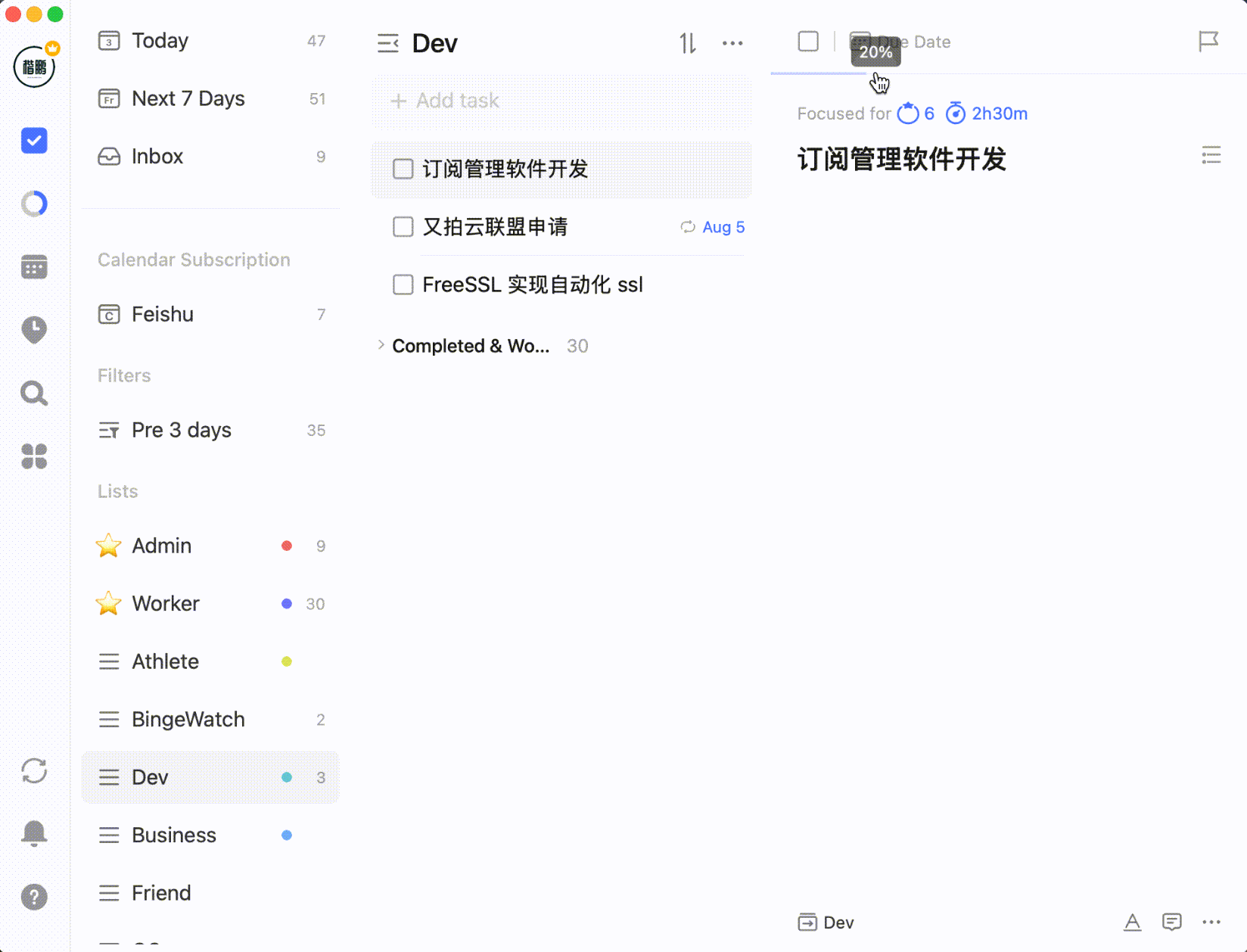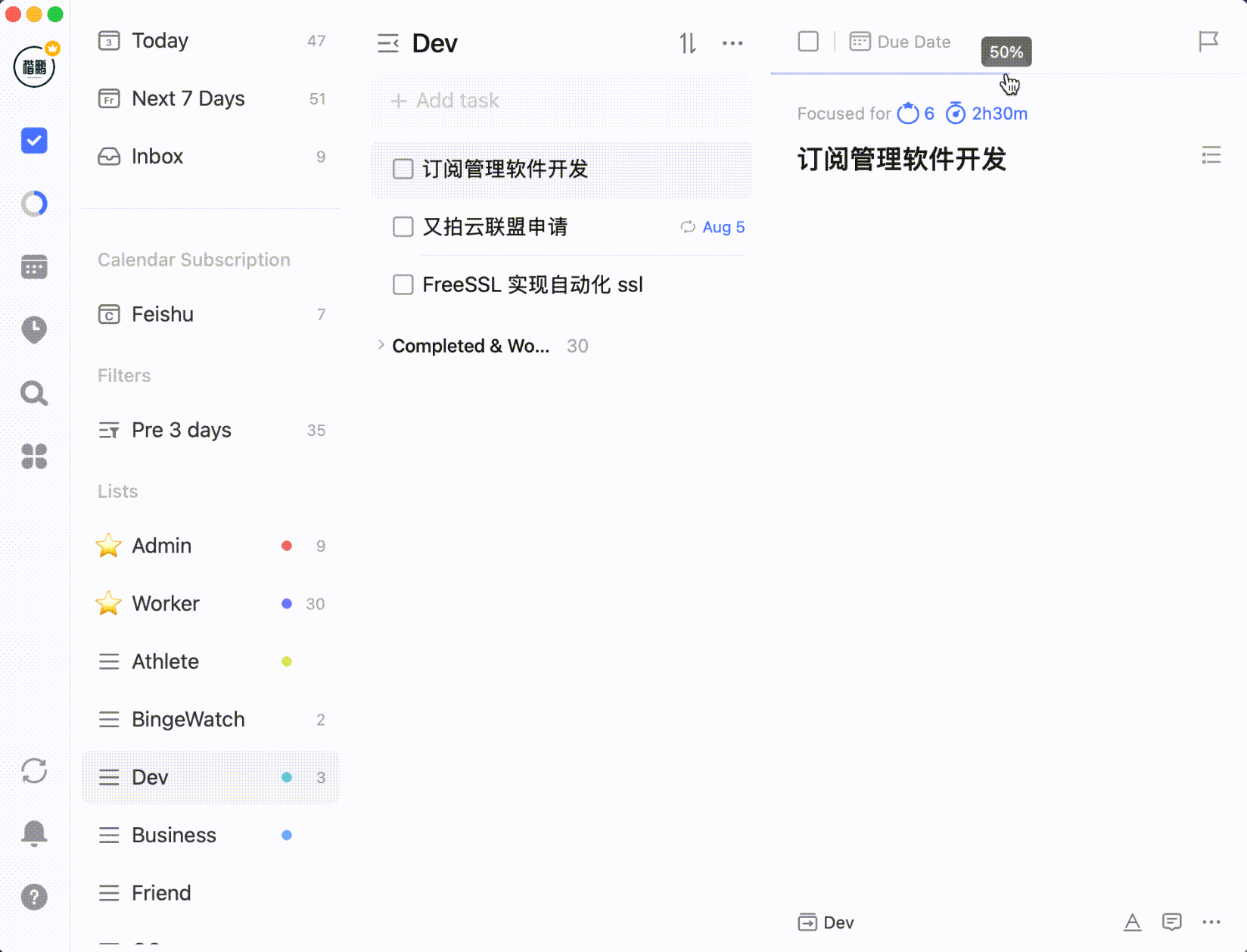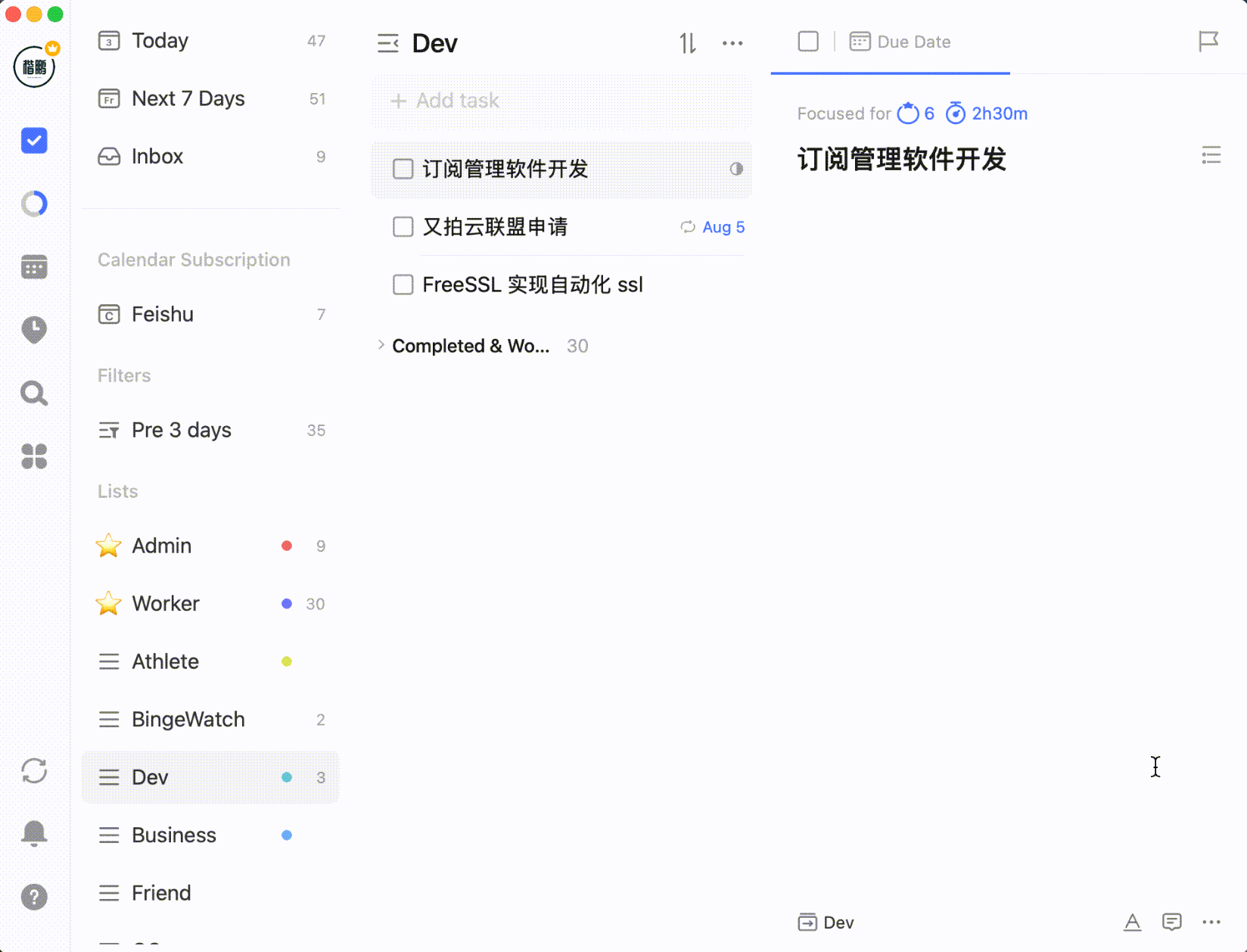
按住 Shift 或者 Command/Control 键选中多个任务之后,能够进行批量处理:
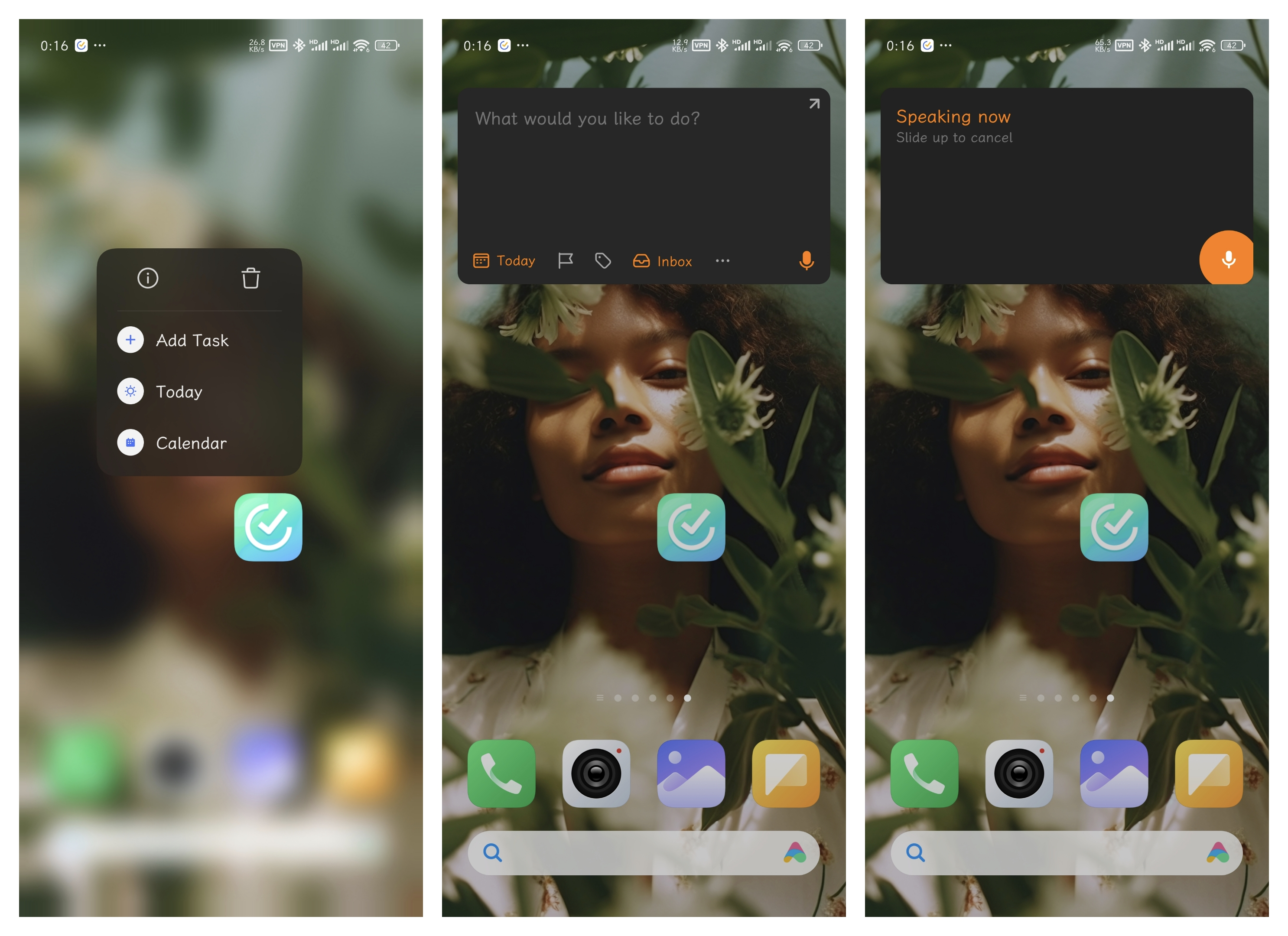
移动端长按应用图标添加任务,任务框右下角有个语音转文字功能,可以加速添加任务时间
另外是日程表功能,之前没有相应的使用习惯,最近发现了两点,让我开始觉得日程表非常香。
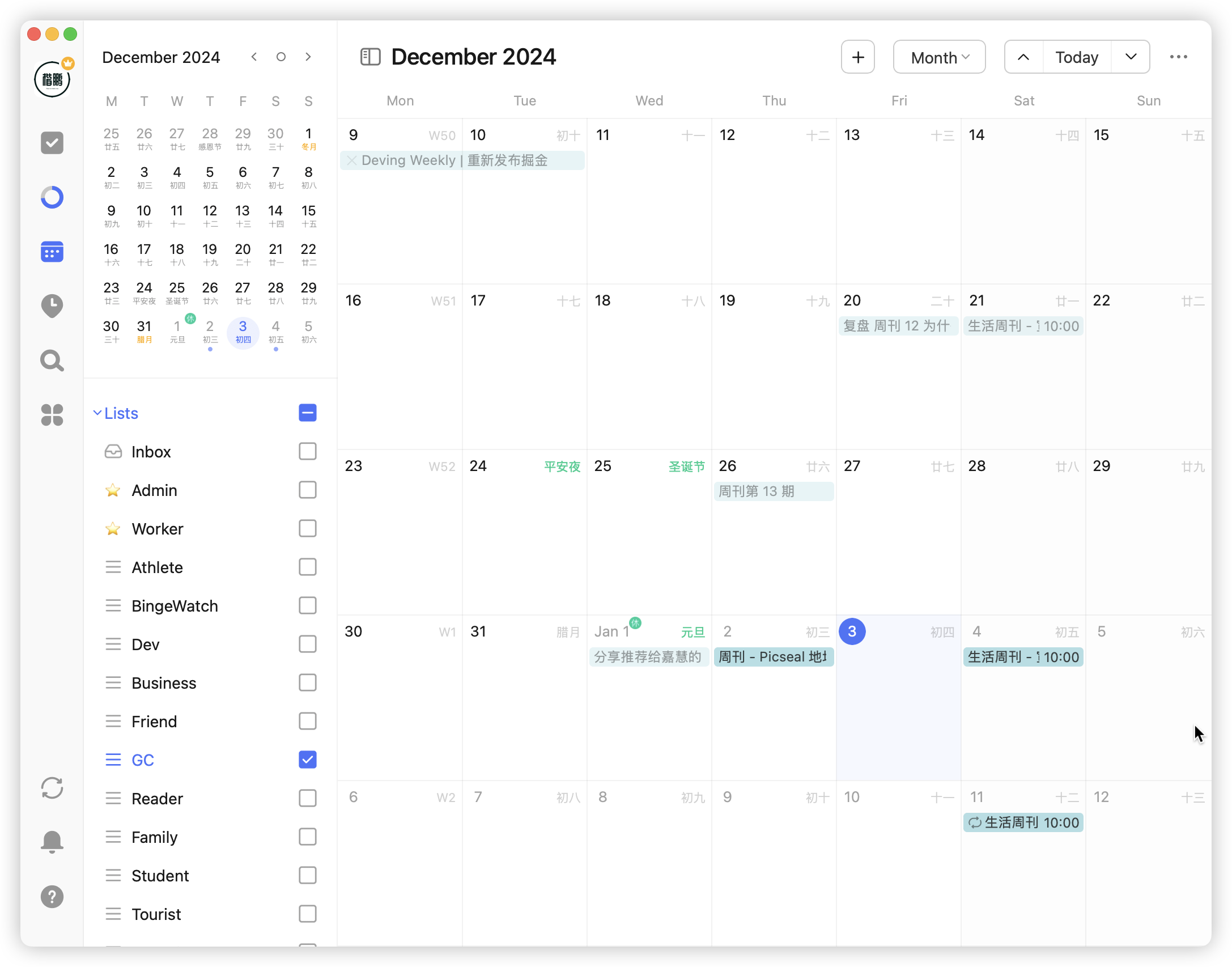
第一点发现是,可以运用筛选面板去查看目标任务,之前没有使用筛选,看着日历上所有任务都堆在一起,一个头两个大:
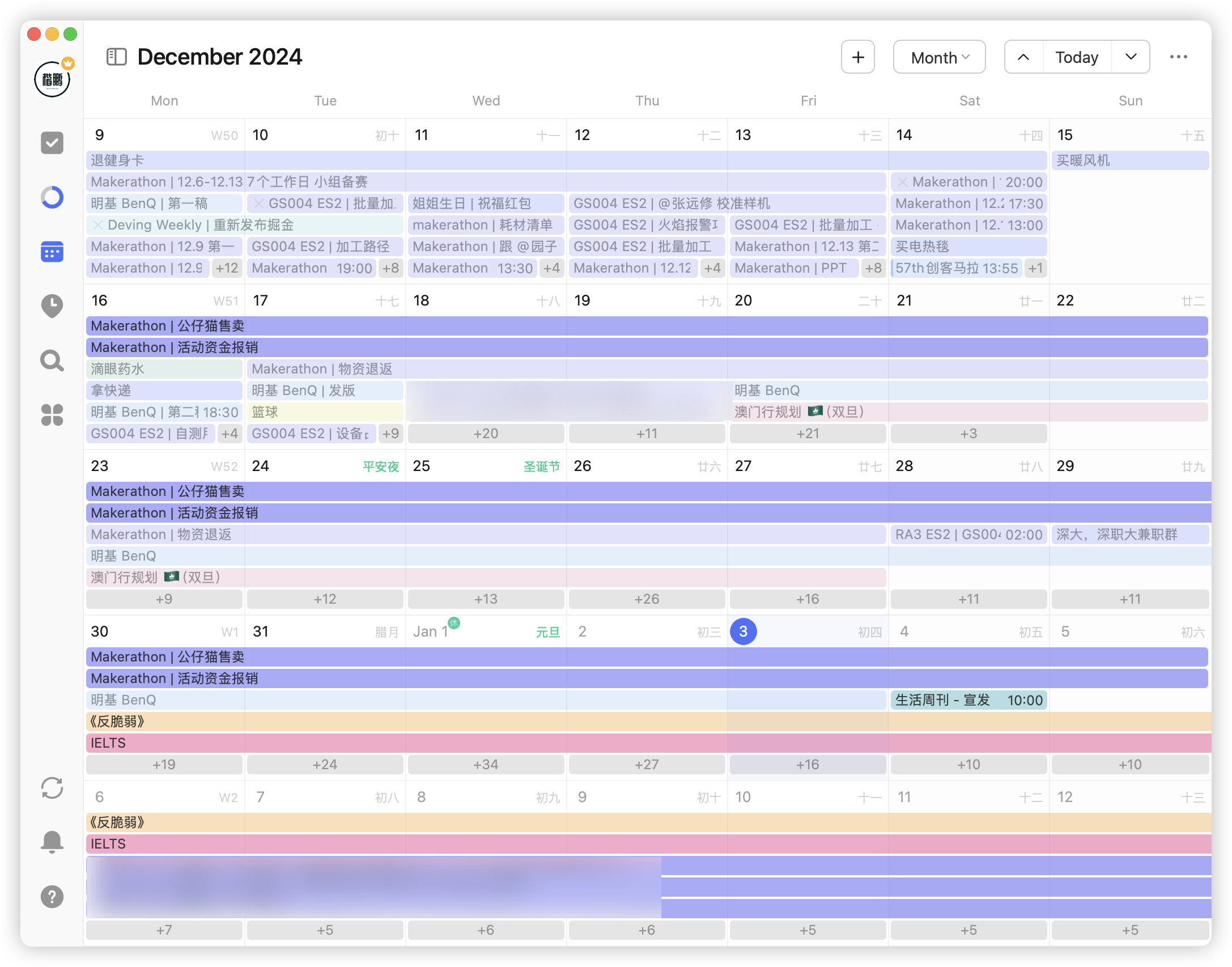
现在使用筛选功能,按照清单、标签等筛选,可以轻松地查看日程对应的任务:
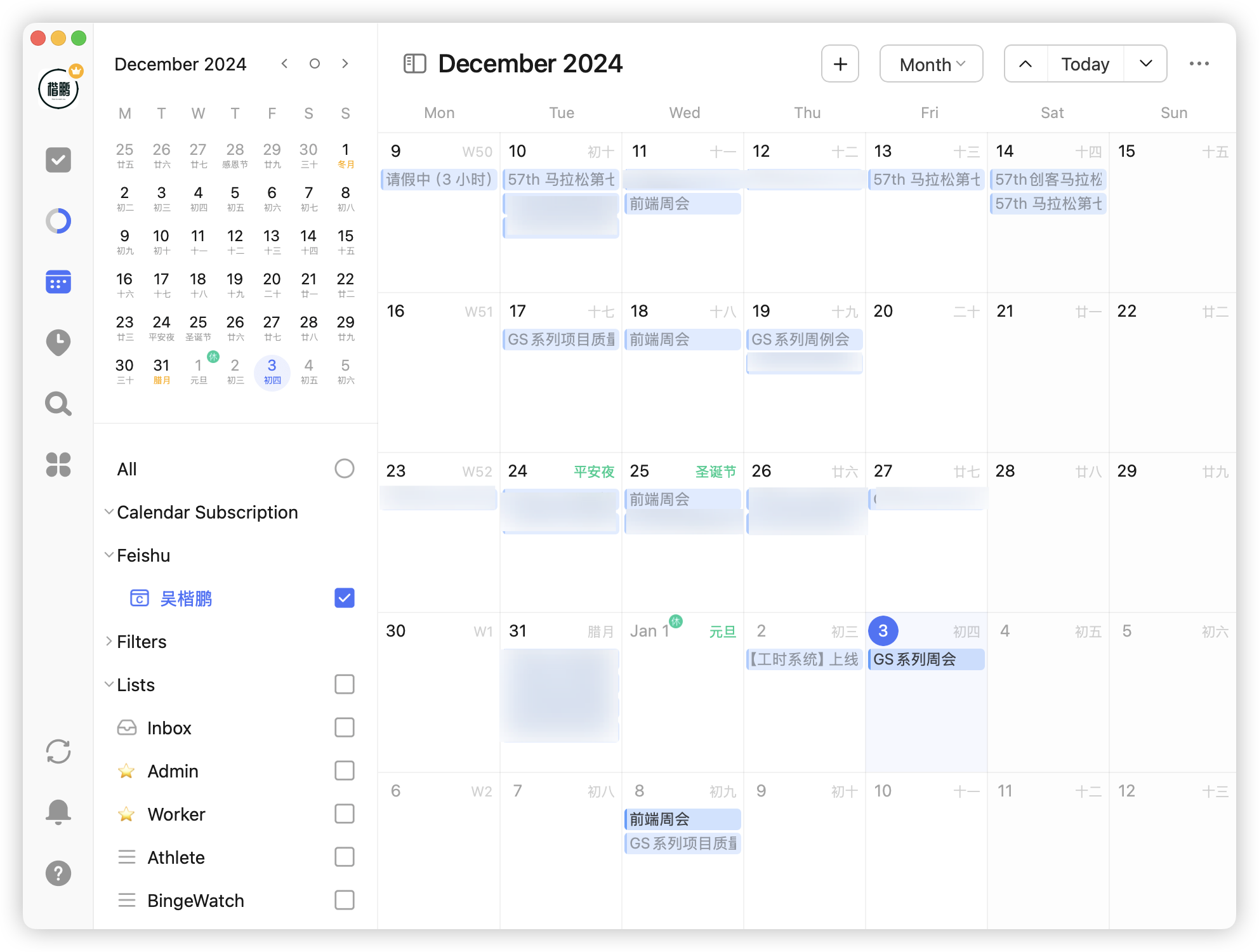
第二点发现是原来日程之间是有通用协议的——CalDAV,它是一种日历数据共享和同步的协议,适用于安卓、iPhone、Windowns、macOS 等一切设备,只需要日历源即可在需要的日历地方导入即可同步到日程。
我在滴答清单上通过导入飞书的 CalCAV 配置,即能实现对飞书所有会议、日程的订阅:
还有一个习惯功能,我挖掘出了三种使用方法:
第一种就是最常用的正习惯:

第二种是坏习惯:
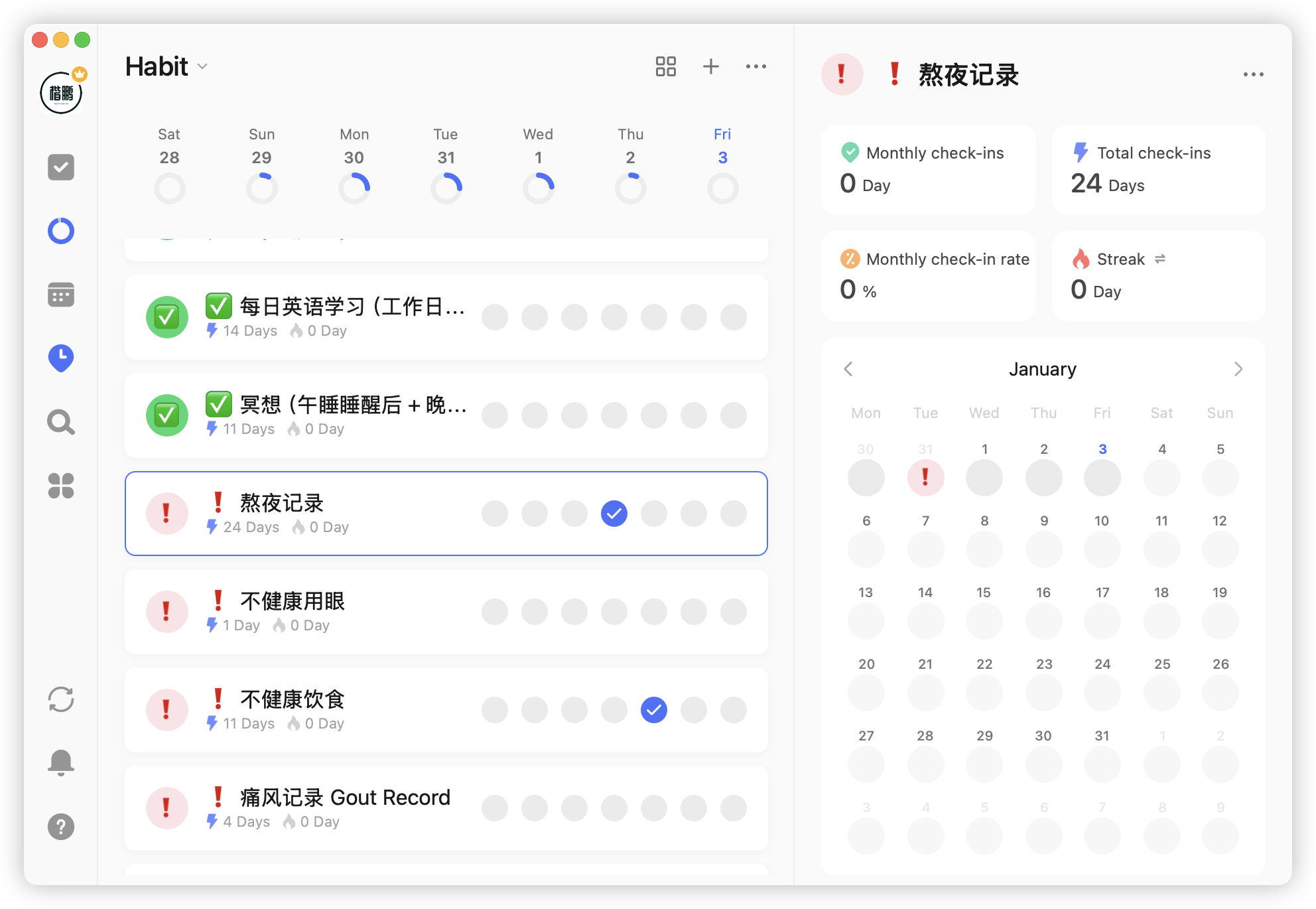 这种和正习惯相反,只有在出现这些坏习惯的时候才会做记录,坏习惯记录的场景是有:
这种和正习惯相反,只有在出现这些坏习惯的时候才会做记录,坏习惯记录的场景是有:
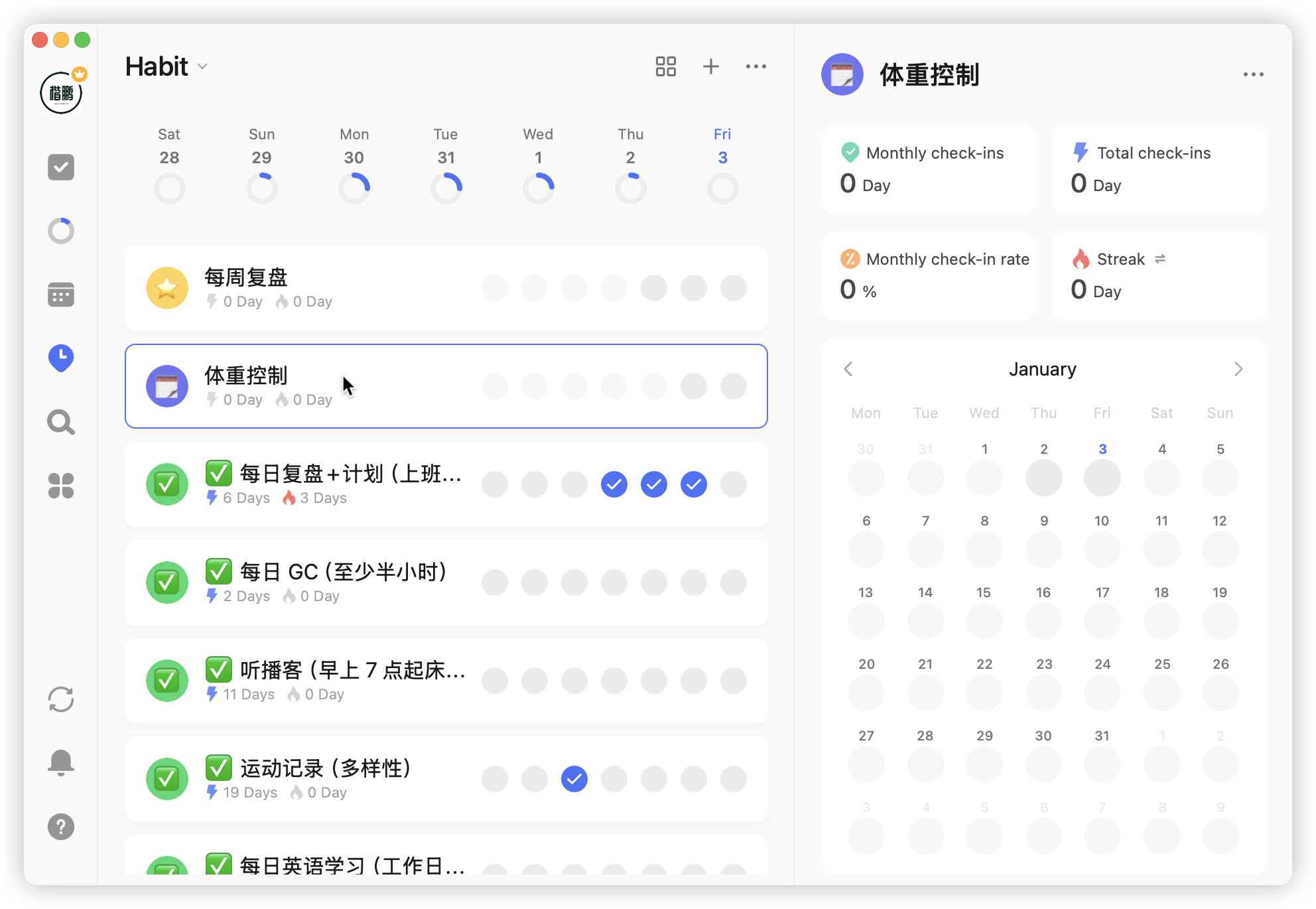
第三是数据记录
习惯是有自带日历,可以当做一个数据记录,比如减肥的过程,可以记录每天的体重情况:
以上就是个人对滴答清单这一年来的使用,这确实是一款优秀的软件,但不可否认,它也存在一些局限性,比如艾森豪威尔矩阵,仅仅是对任务进行重要性、紧急性做一个简单的二维划分:
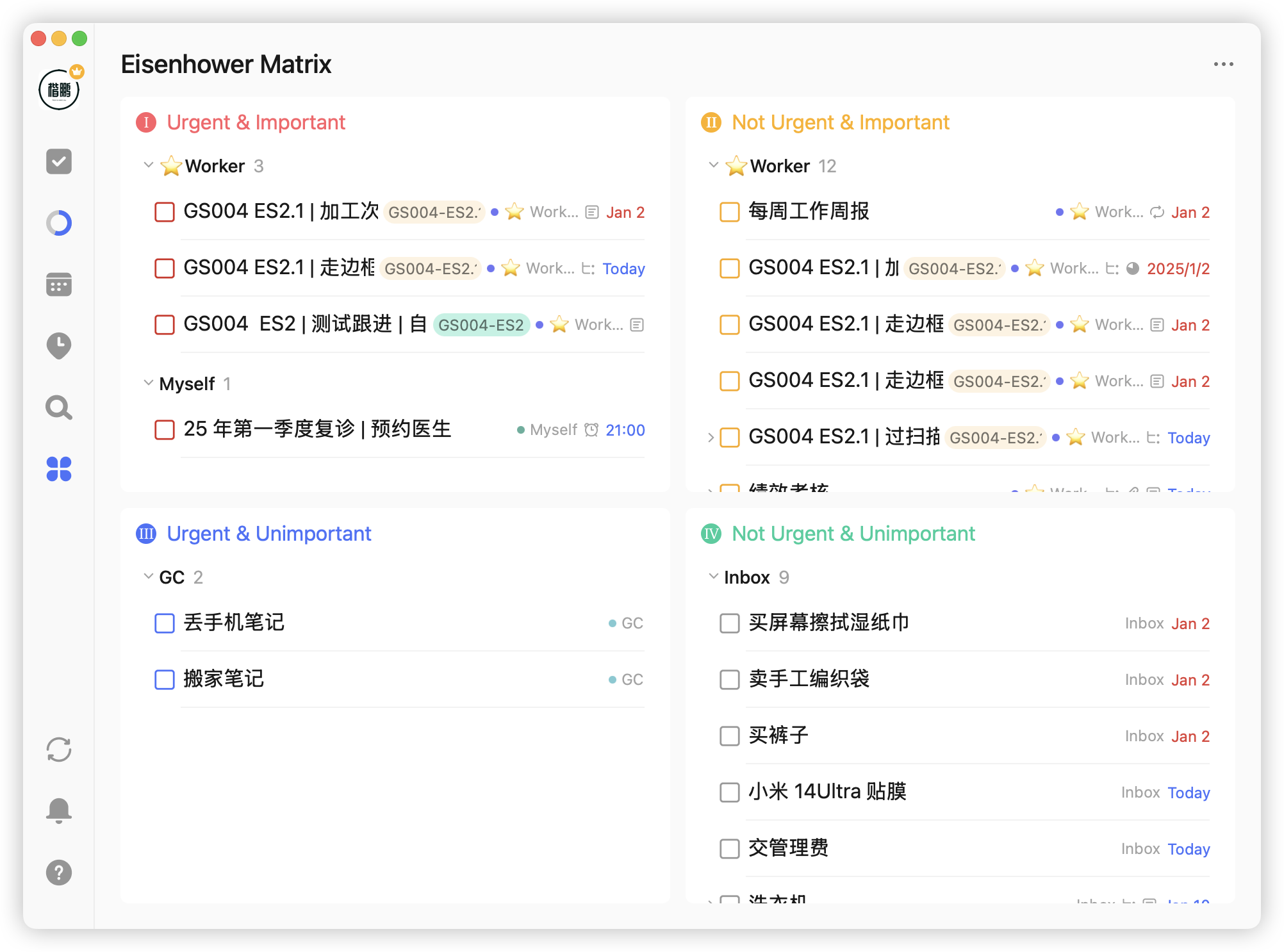
但这世界上不可能有完美的软件,有问题就解决问题,2024 年陆陆续续给滴答清单提的 bug 加上 feature request,有将近 30 个:
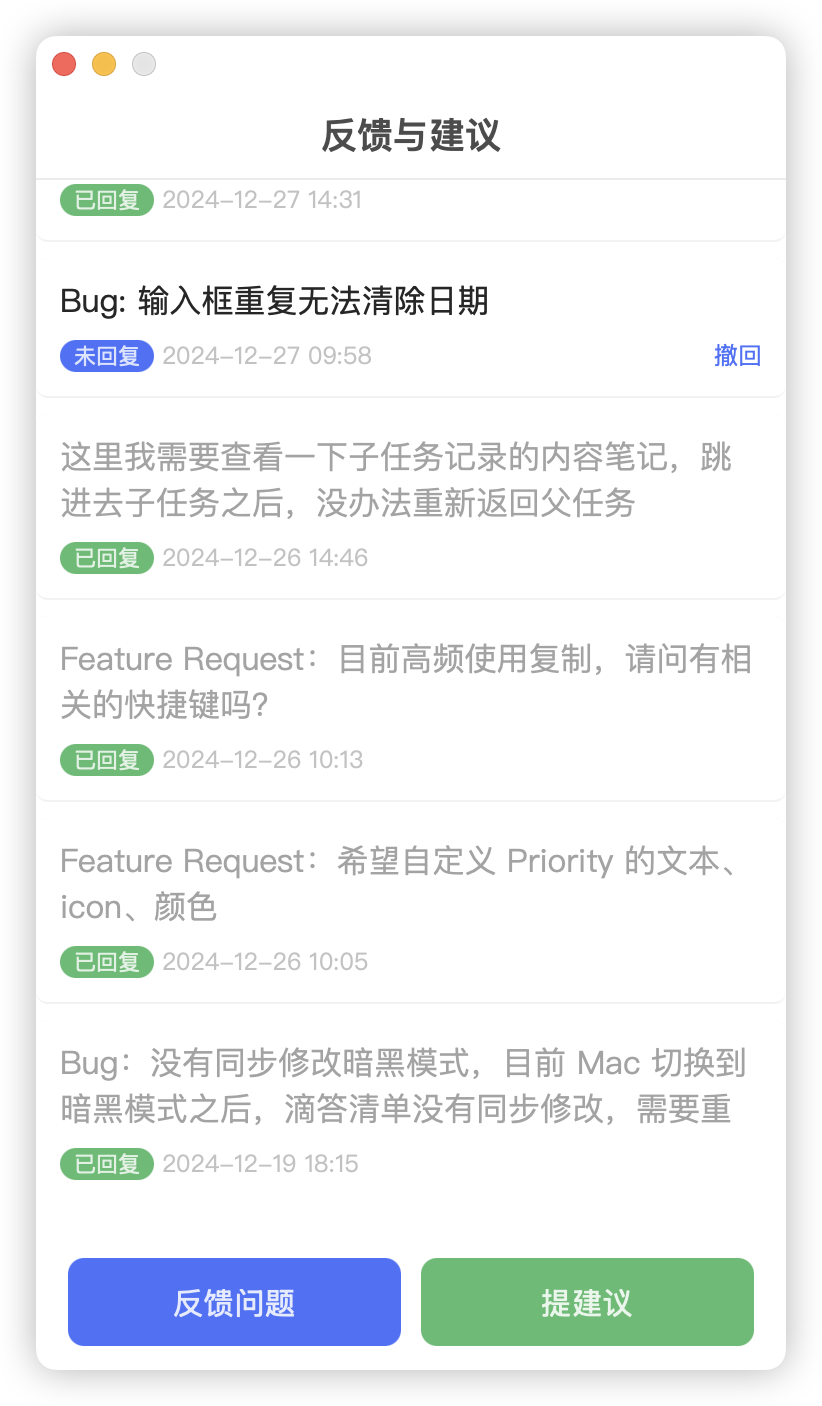
所以,我这算是编外的测试人员 + 产品经理吗 😆