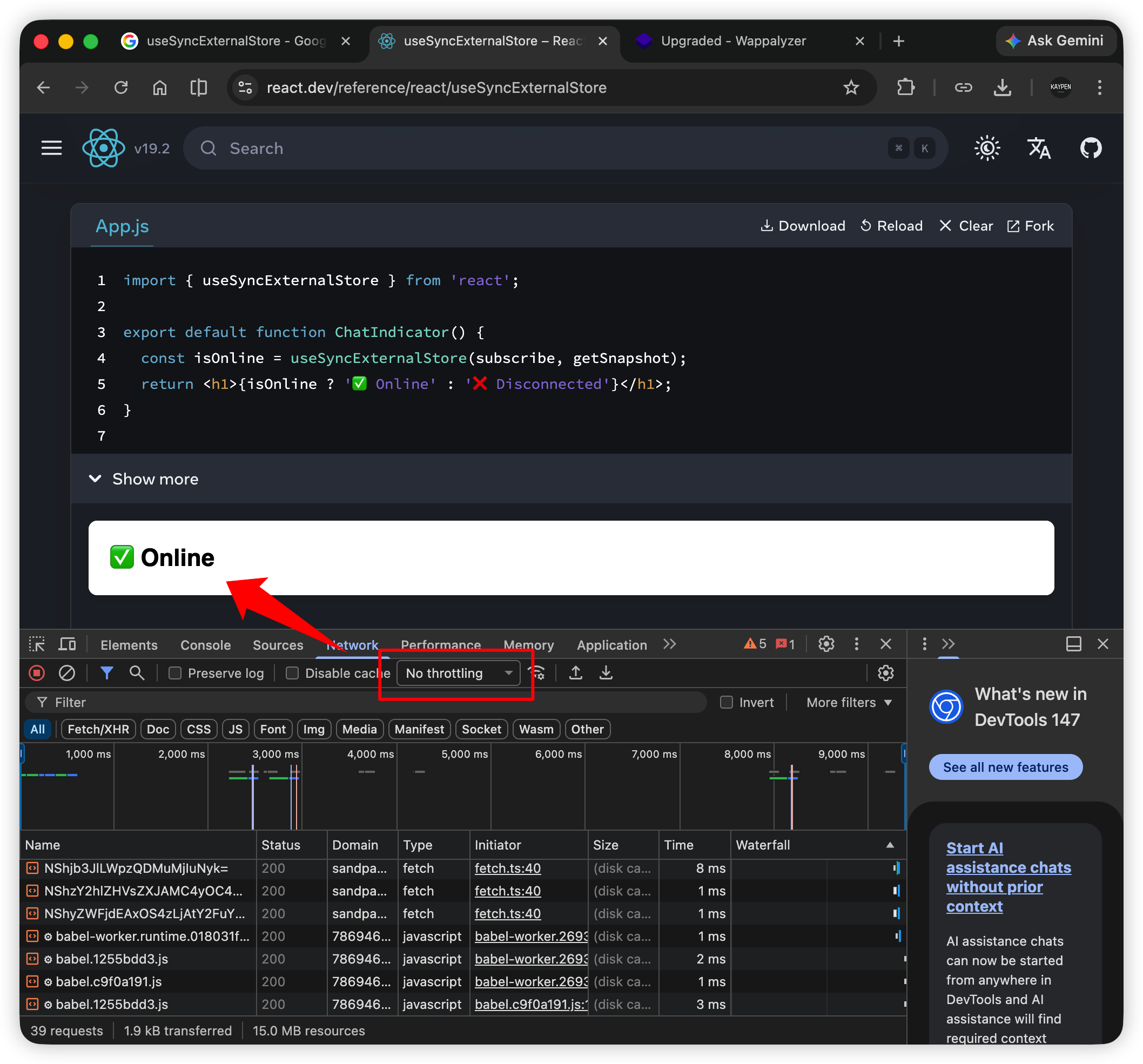
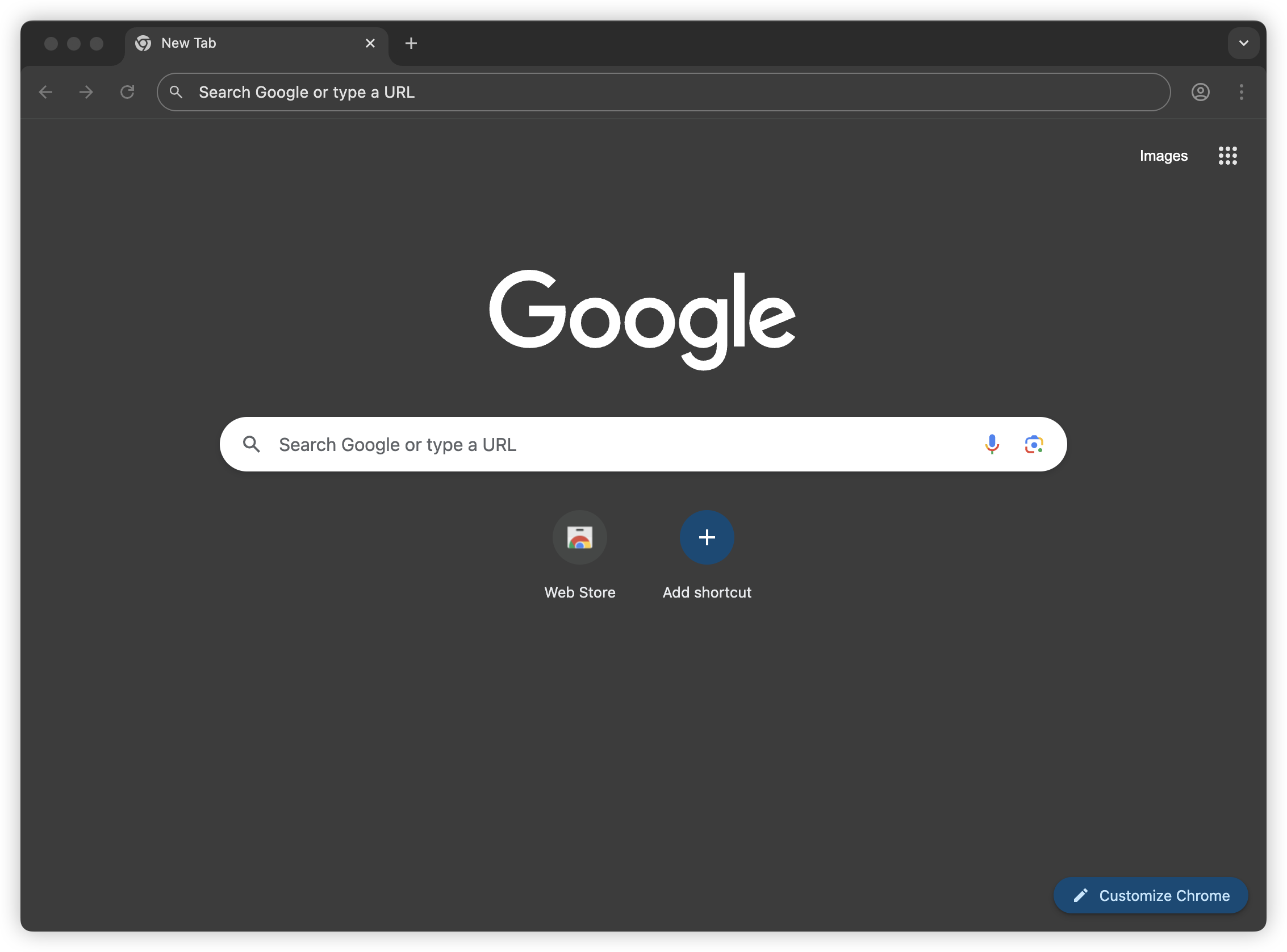
Raycast's 2024 annual statistics are out. These stats include how many times I used Raycast to open other apps throughout the year. Seeing TickTick opened over a thousand times, ranking first, was a bit surprising.
TickTick's Chinese name: 滴答清单
This year was my first year trying and gradually becoming a heavy user of TickTick. Initially, I just wanted to find a task management software. After comparing many other todo apps, TickTick's free version is what I personally consider the most generous - covering most features.
While the free aspect was tempting, it wasn't enough to win me over. What really convinced me was how it solved my long-standing pain points.
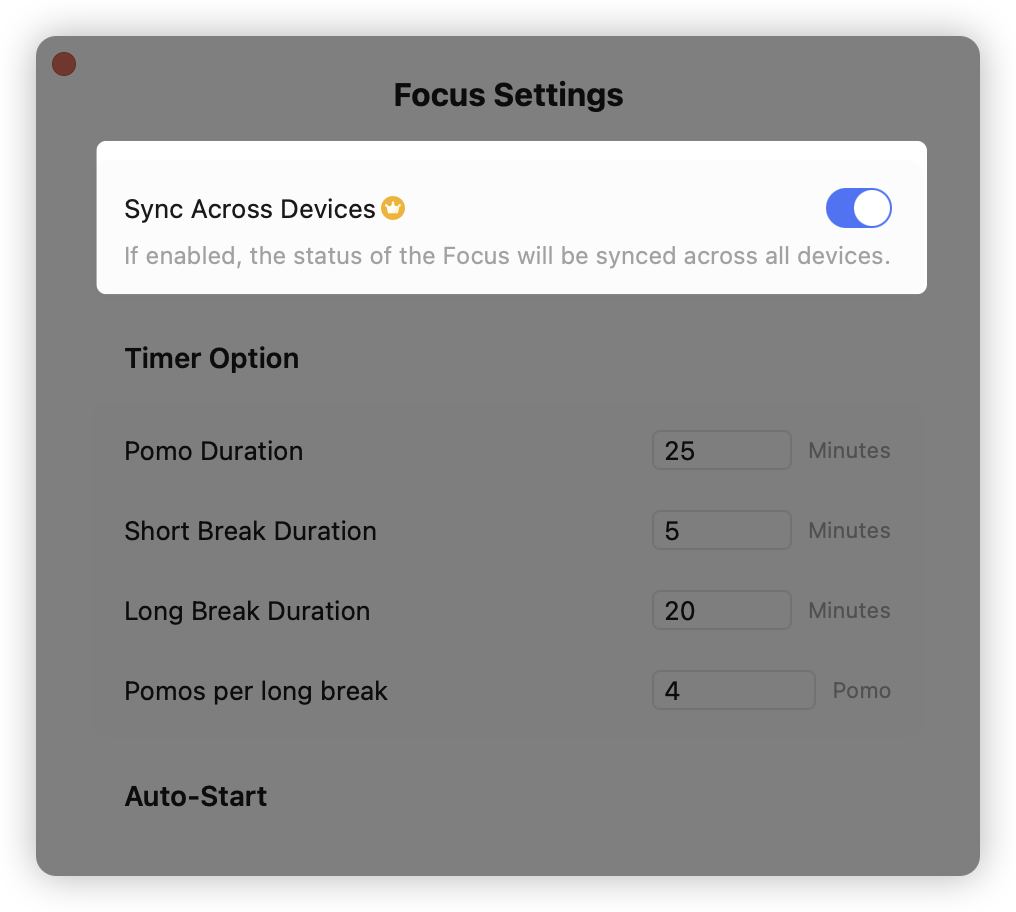
When working on tasks, I use the Pomodoro Technique, which means focusing for 25 minutes (1 Pomodoro), then taking a 5-minute short break, and after accumulating 4 Pomodoros, taking a long break - this cyclical rhythm for focus.
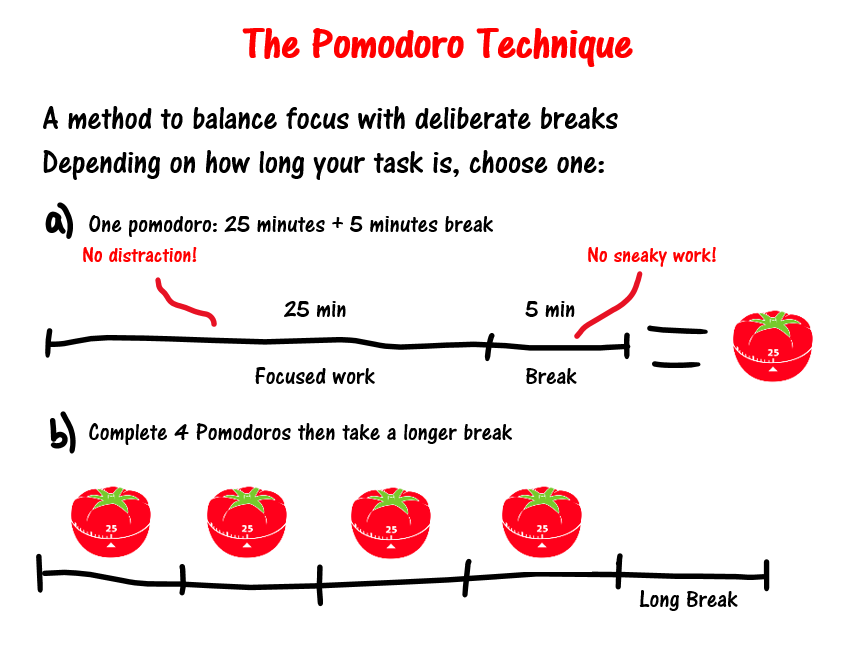
Previously, I bought a desktop timer clock. Students preparing for exams should be familiar with this - something like this:

This timer can count up or count down, perfect for a 25-minute Pomodoro countdown. I used this for over 2 years, buying one for home and another for the office.
It's convenient - physical buttons, one press to start a Pomodoro. But its advantage is also its disadvantage.
Physical limitations mean I can't carry a timer everywhere. More troublesome, at the end of the day, I don't know how many Pomodoros I spent, when I started them, or what tasks I worked on during each Pomodoro.
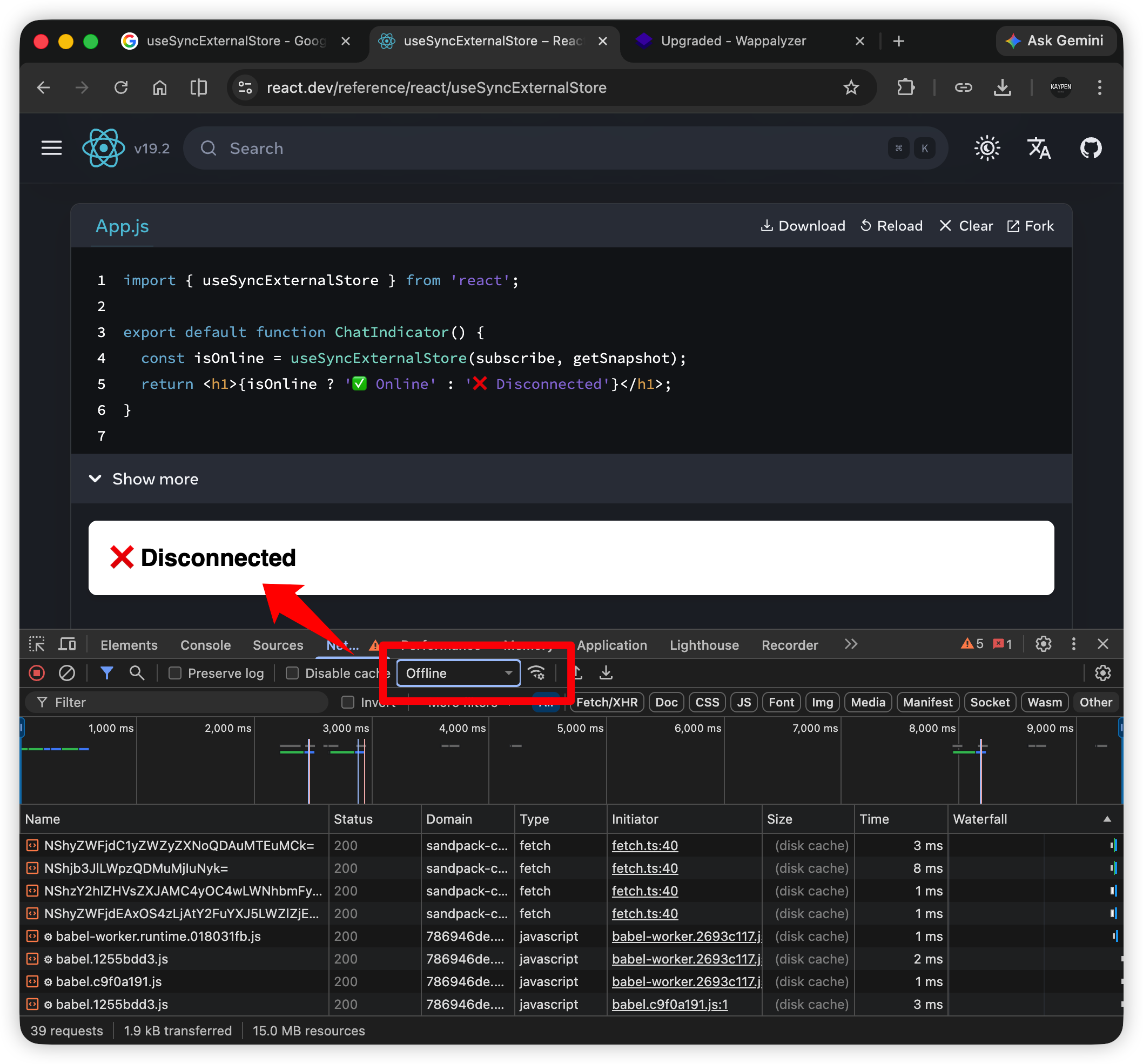
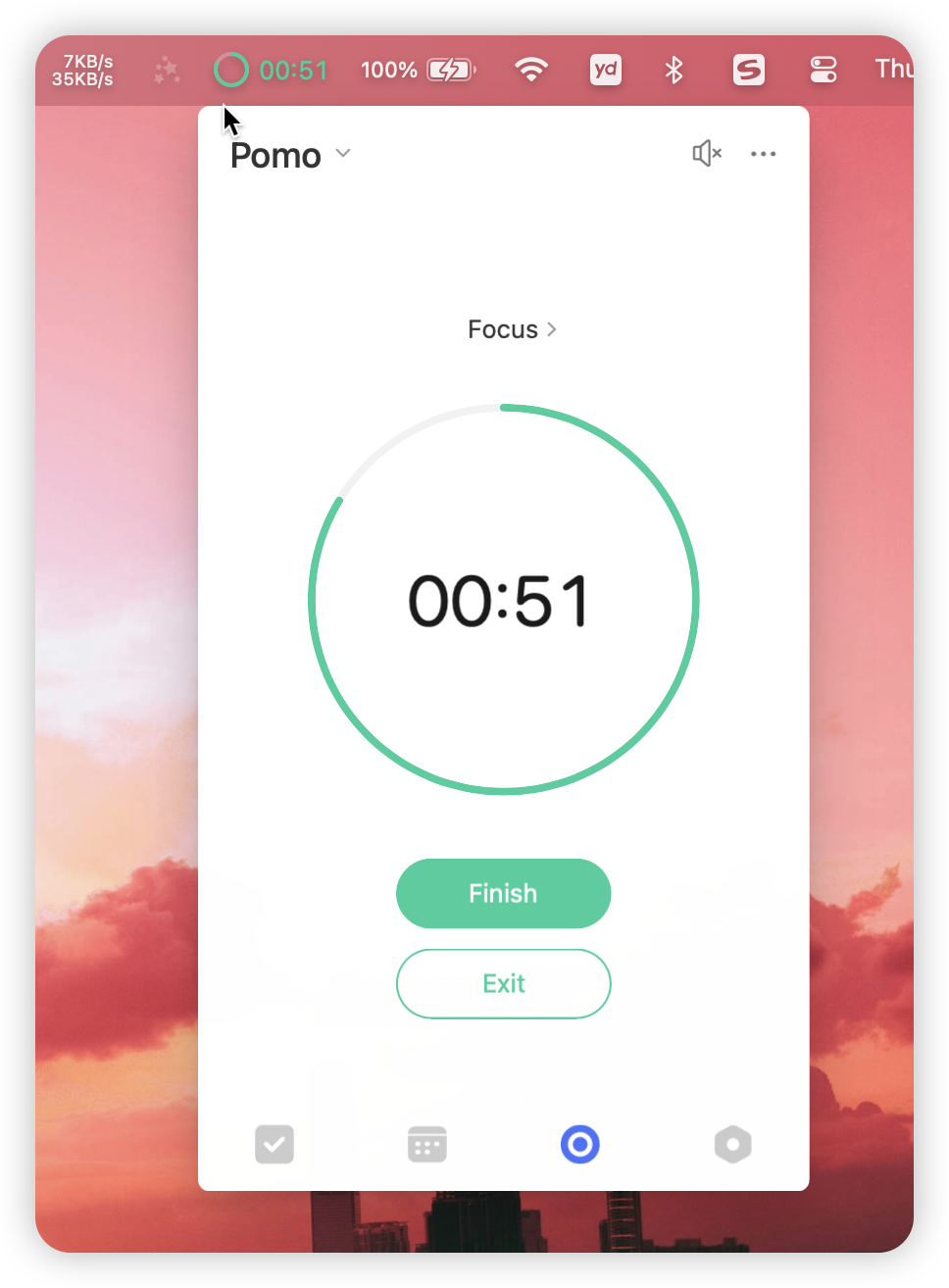
In TickTick, after adding a task, you can directly start a Pomodoro for that task, or associate tasks with ongoing Pomodoros, while adding notes. Opening the statistics page clearly shows the start and end of each Pomodoro.

This basically solved my major pain point. Another minor itch was its notification feature. I often forget to start Pomodoros, but TickTick shows focus progress explicitly in the computer's menu bar:
If cross-device sync is enabled, both phone and computer will sync current focus progress in real-time:
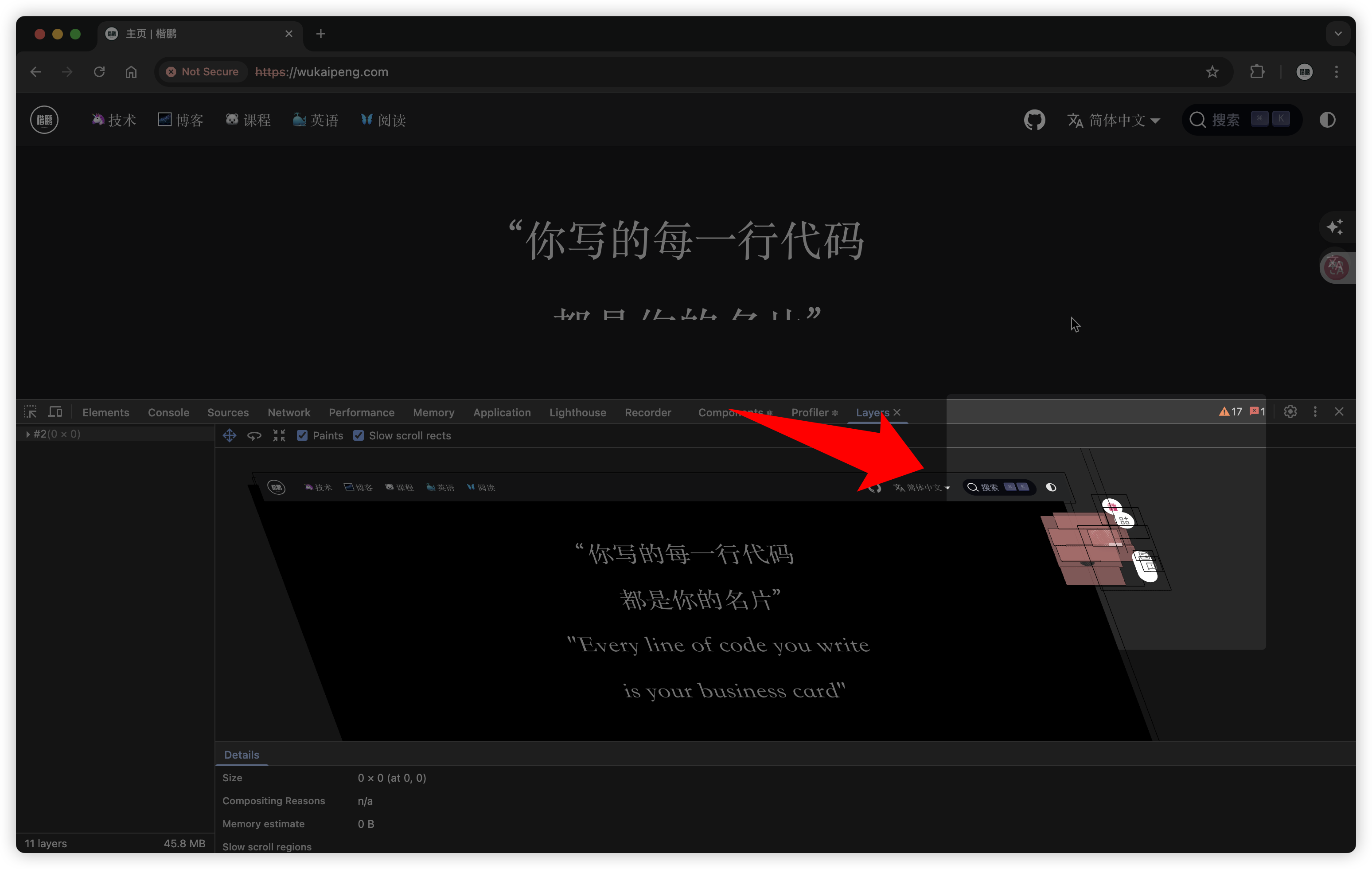
What pleasantly surprised me was that after enabling focus mode on mobile, it automatically enters immersive mode. Besides the flip clock mode, there's this pixel mode with particularly beautiful UI:

After TickTick solved my Big Trouble, I started exploring other features.
For the core function - task management, the first point is task categorization. I believe many people's categories are quite messy, adding a "Reading" category today, a "Project Management" category tomorrow. Once categories multiply, they become hard to manage.
Here I recommend a very practical categorization method: categorizing by "roles"
At work, the role is "Employee"; at school, it's "Student"; on the track, it's "Athlete". In any social relationship, everyone plays different roles.
In my personal TickTick categories, I have roles like Admin, Worker, Developer, Friend, Reader, etc.
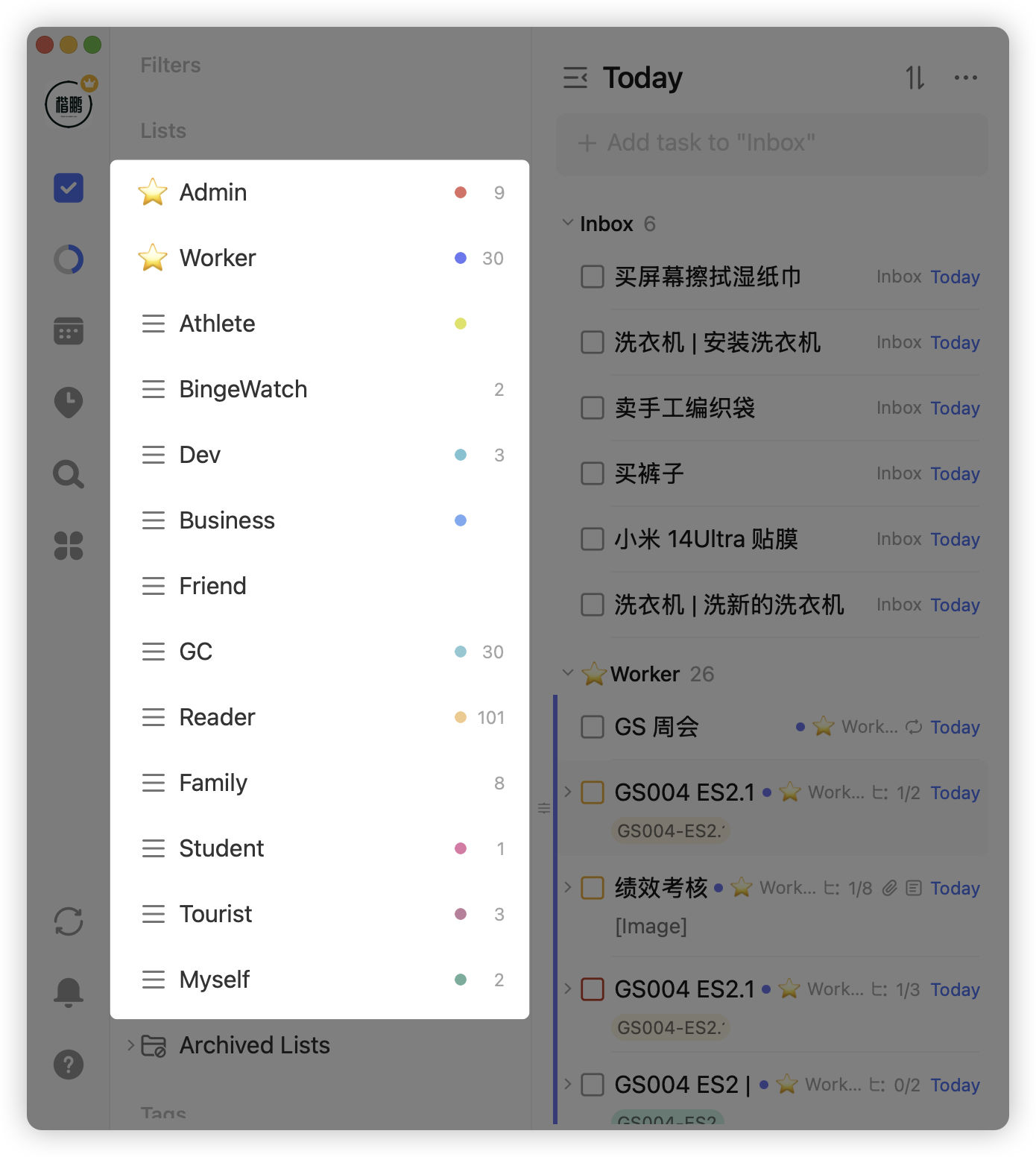
This division method is very stable. Once my task categories were divided, there were almost no major changes. It's also flexible enough - for example, if you become a father, just add a "Father" role, and tasks like buying formula and changing diapers go under this role.
Categorizing by roles covers almost everything, but some roles need horizontal expansion. For instance, as an employee, you need to work on project a, project b, project c, etc. You can use tags to label tasks accordingly, distinguishing different task types under roles:
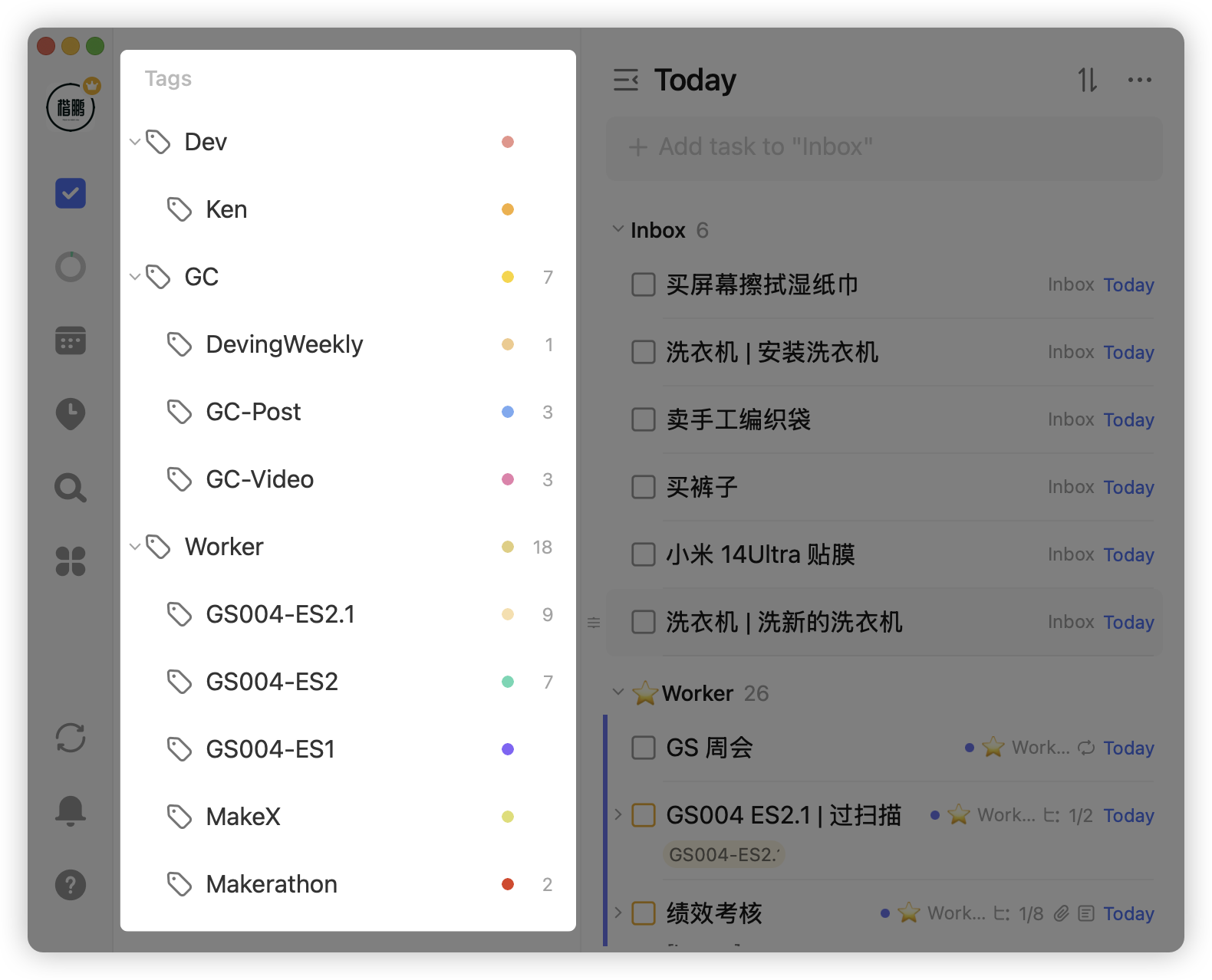
Through role division + tag system, you can basically establish an orderly and stable categorization system.
The second point is task processing. TickTick hides many thoughtful features, like setting the estimated number of Pomodoros for a task:
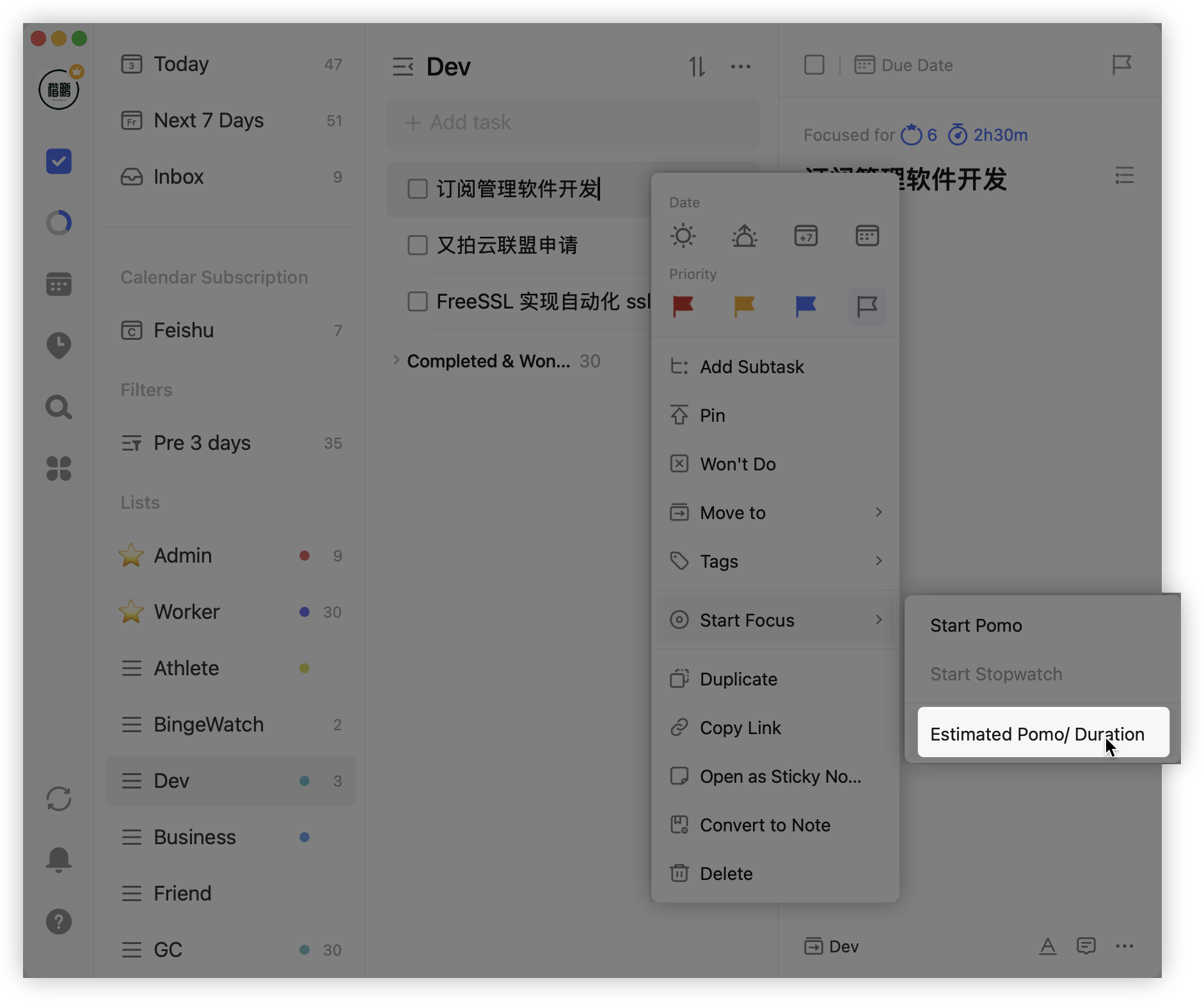
Or setting task progress percentage:
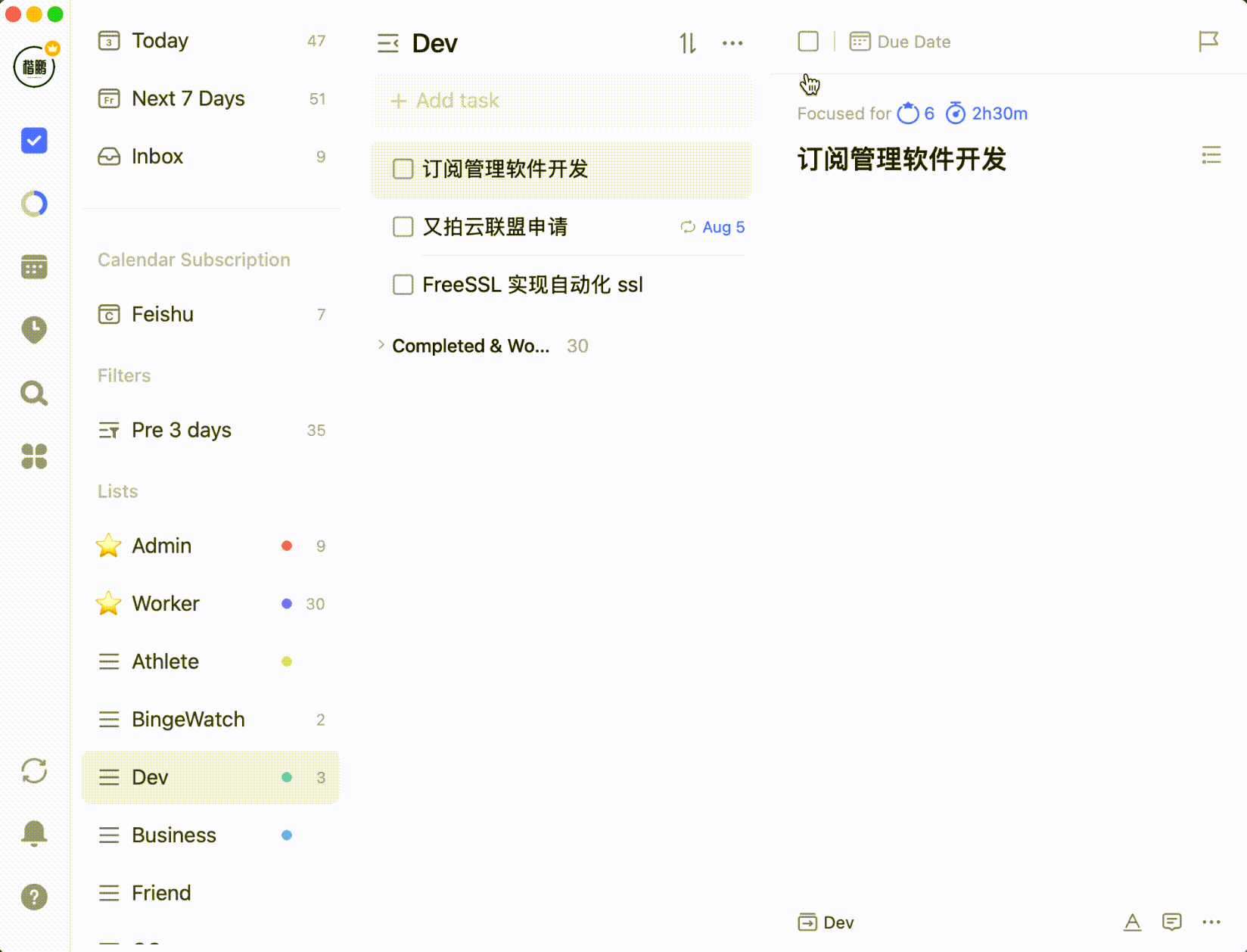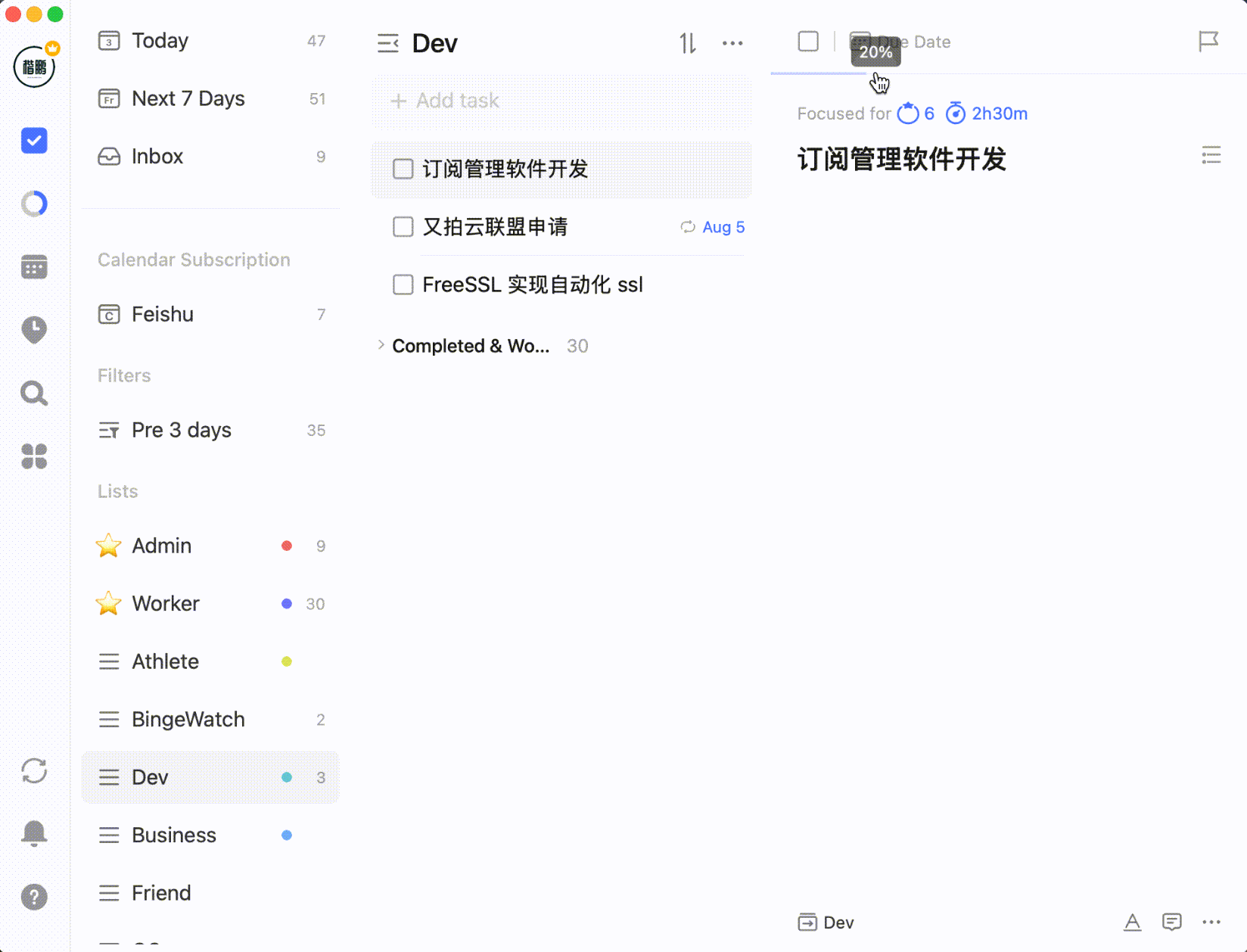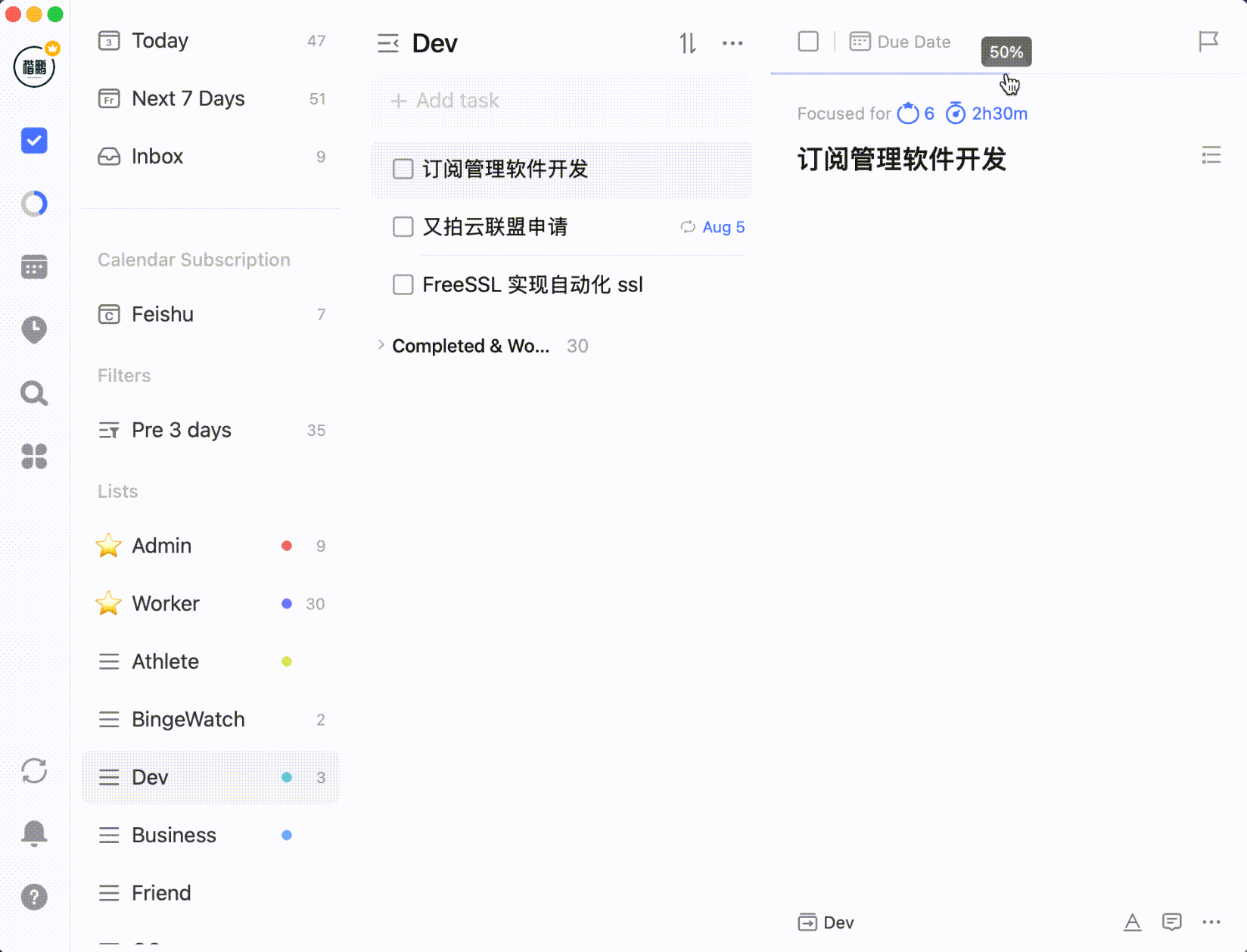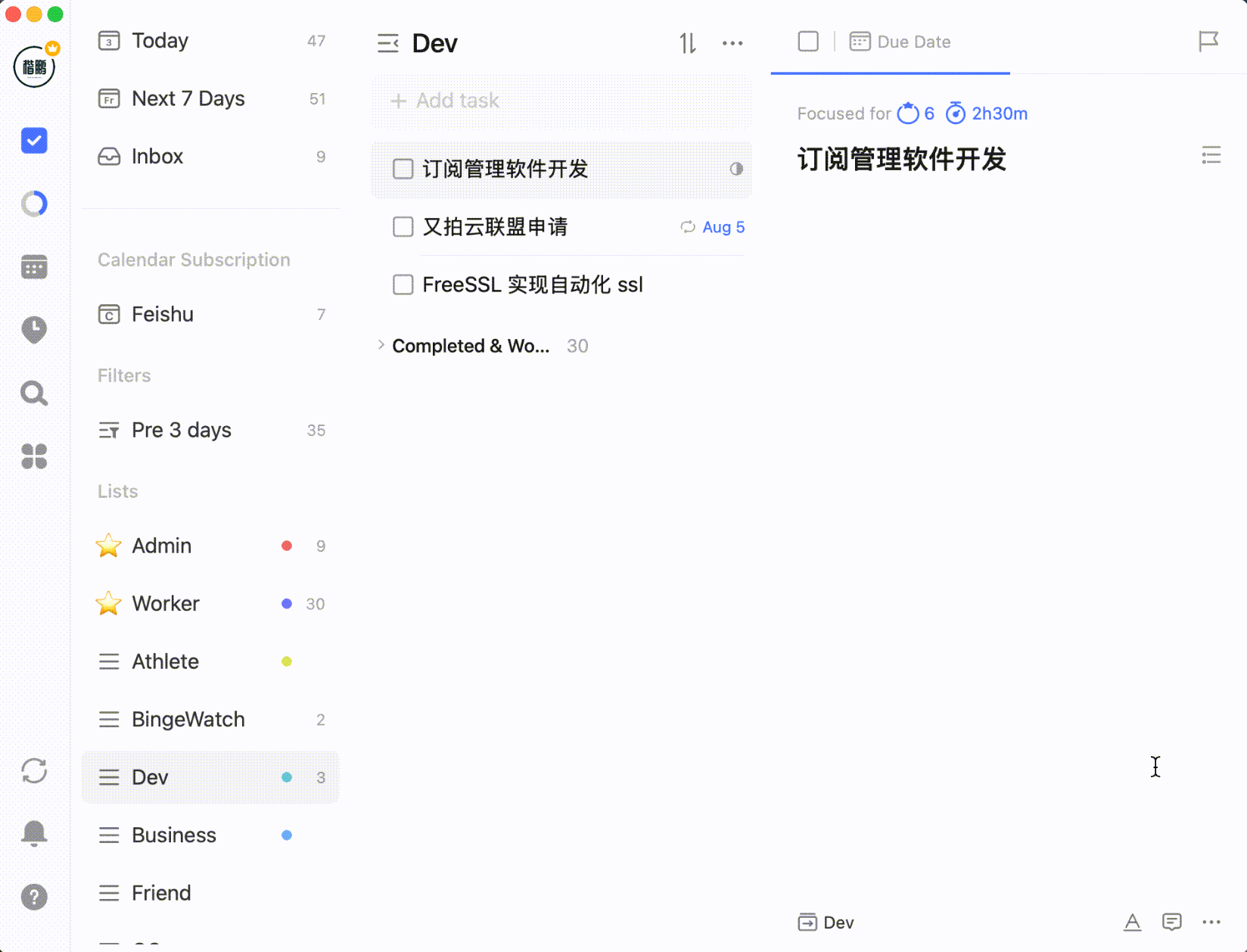
After selecting multiple tasks by holding Shift or Command/Control, you can batch process them:
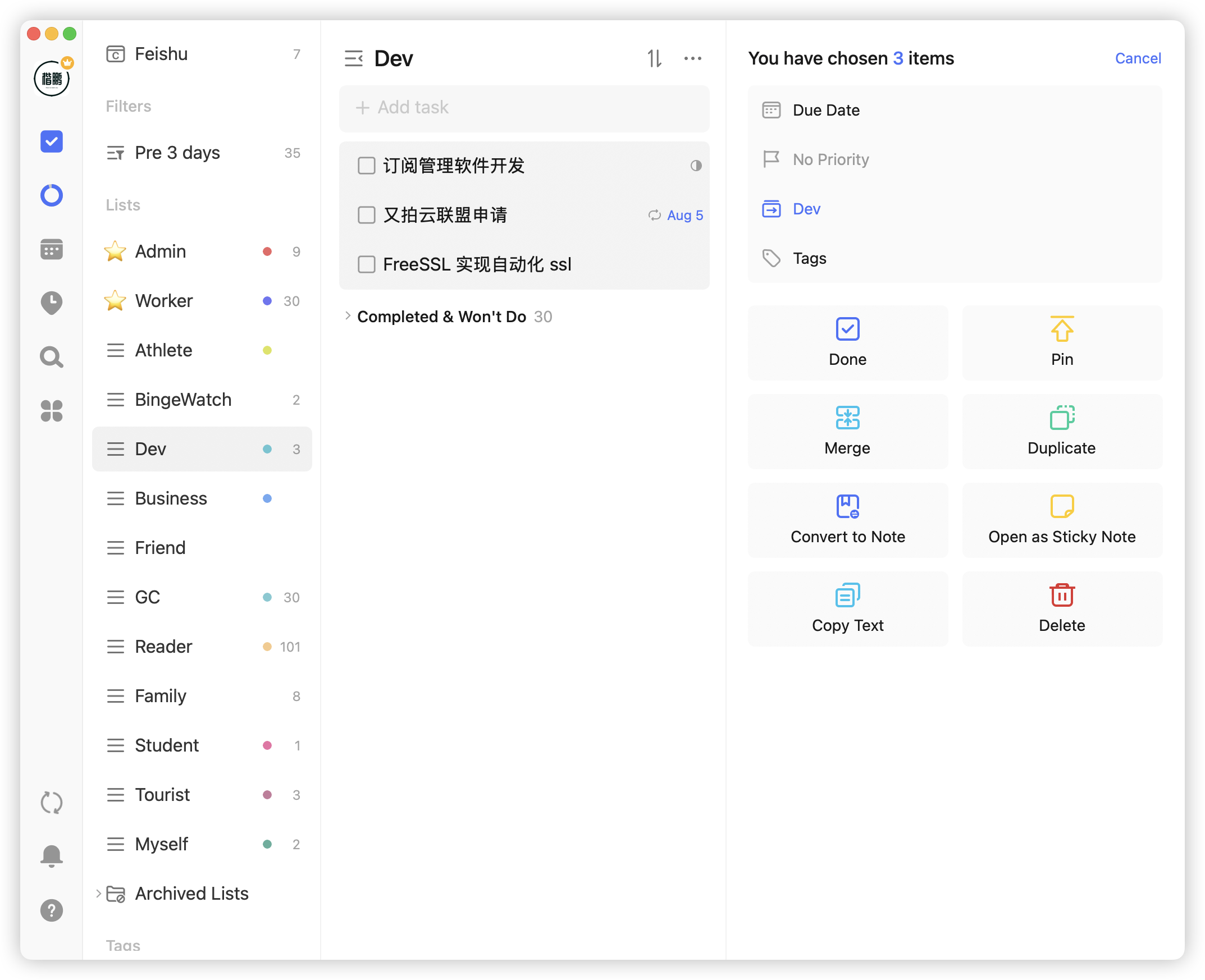
On mobile, long-press the app icon to add tasks. The task box has a voice-to-text function in the lower right corner to speed up task addition:
Another feature is the calendar. I didn't have the habit of using it before, but recently discovered two points that made me realize calendars are amazing.
First discovery: you can use filter panels to view target tasks. Previously without filters, seeing all tasks piled together on the calendar gave me a headache:
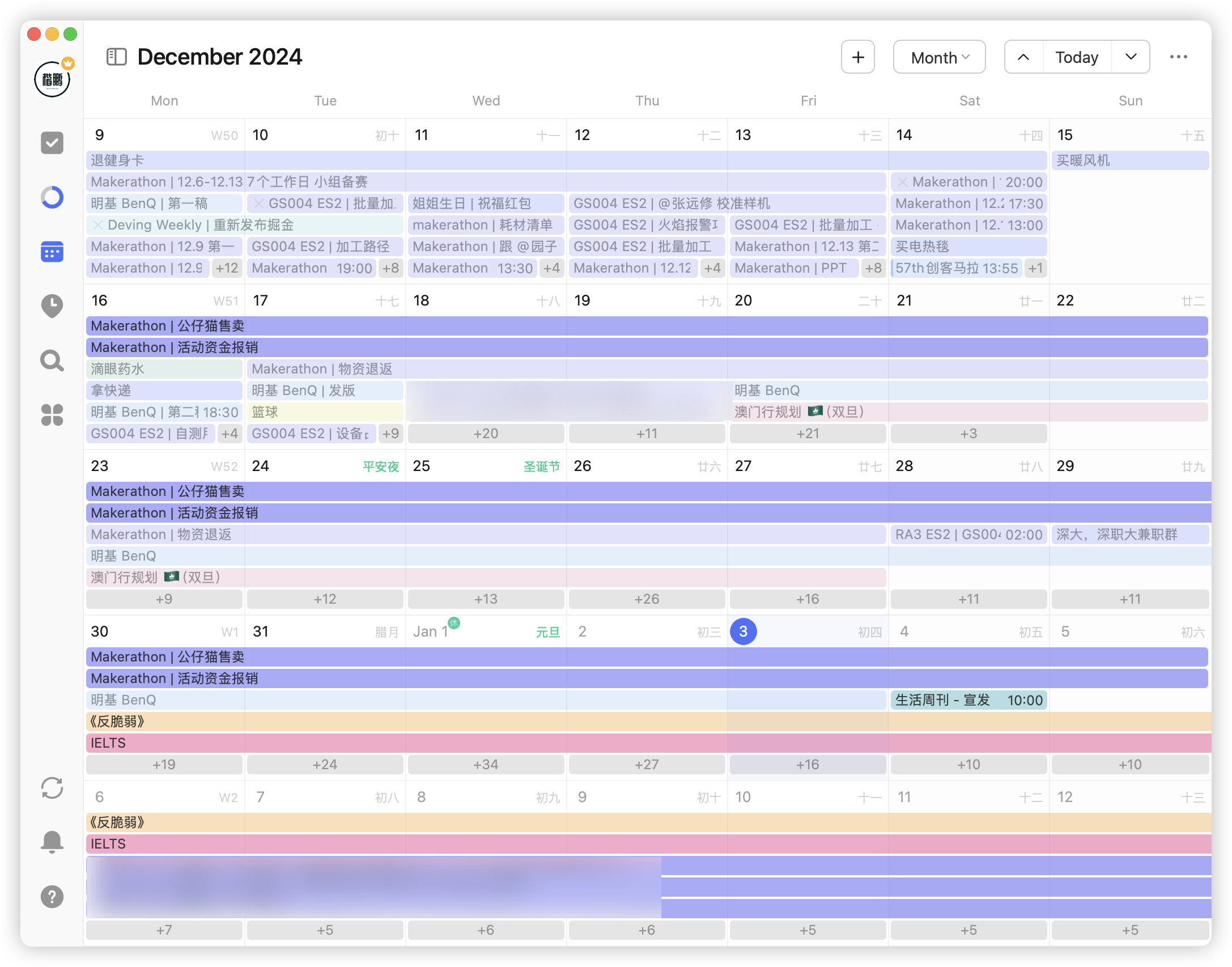
Now using filters by list, tags, etc., you can easily view tasks corresponding to schedules:
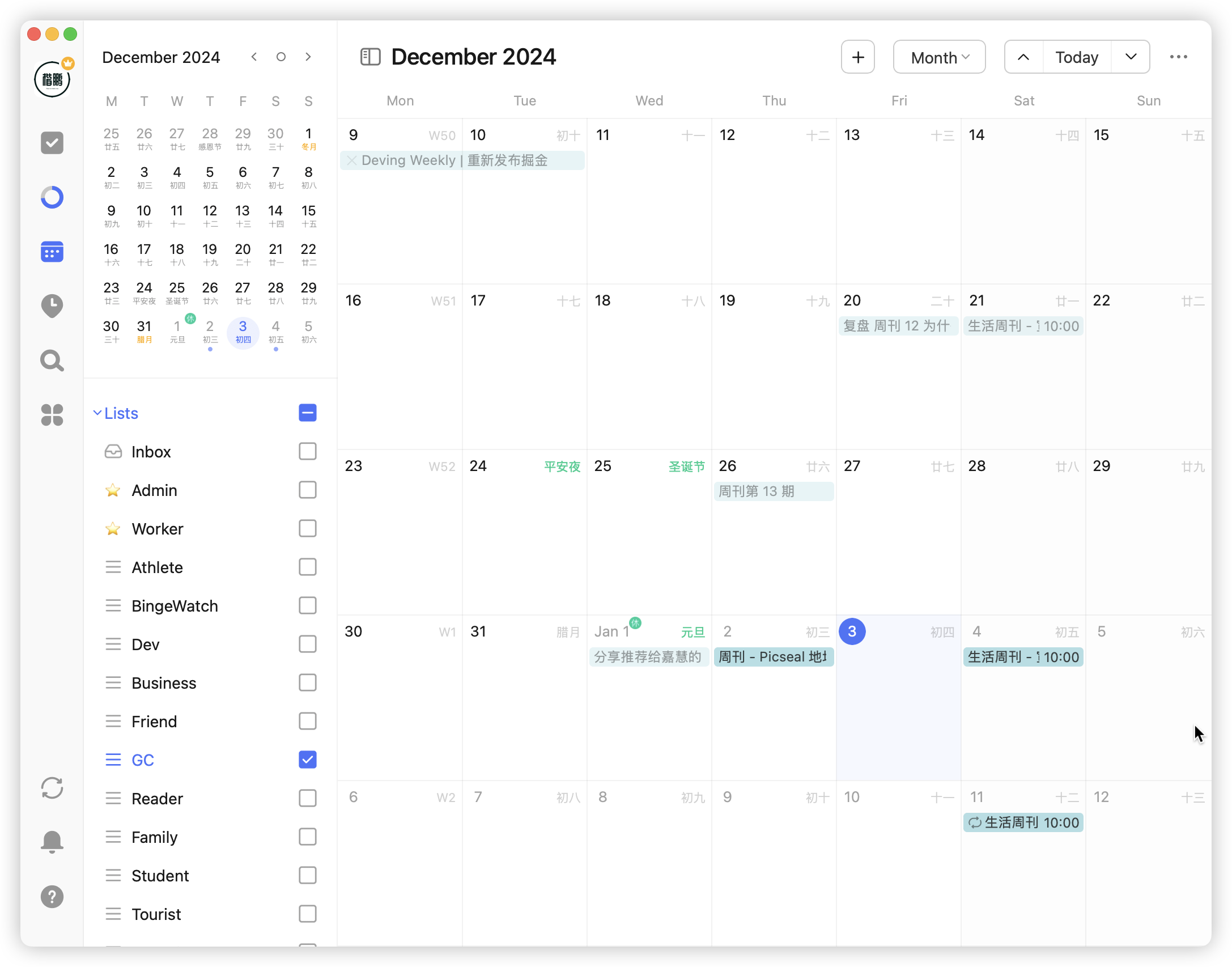
Second discovery: calendars have a universal protocol - CalDAV, a protocol for calendar data sharing and synchronization, applicable to Android, iPhone, Windows, macOS, and all devices. Just need the calendar source to import and sync schedules anywhere.
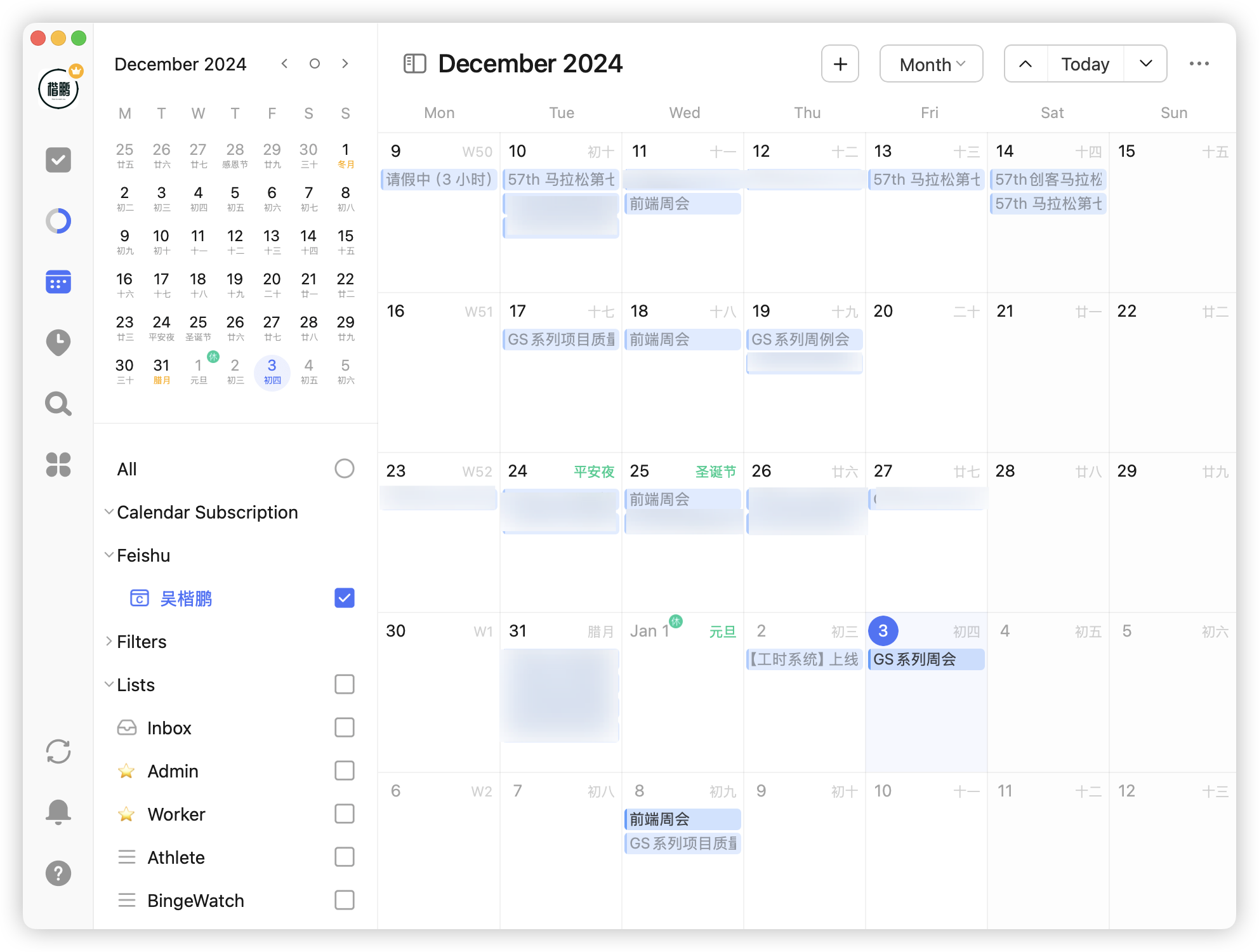
In TickTick, by importing Feishu's CalDAV configuration, I can subscribe to all Feishu meetings and schedules:
There's also a habit function, for which I discovered three usage methods:
First is the most common positive habits:

Second is bad habits:
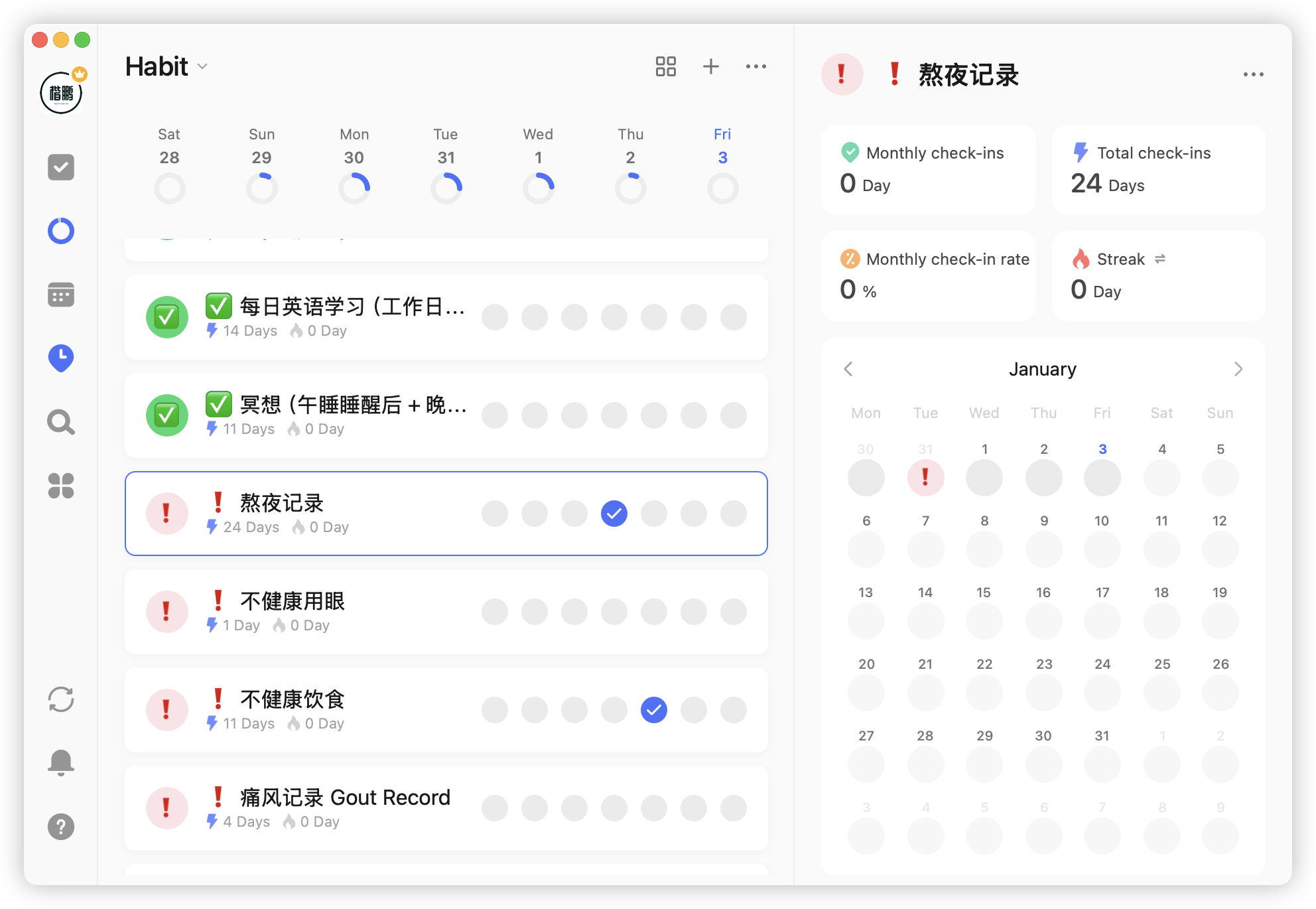 This is opposite to positive habits - only recording when these bad habits occur. Scenarios for recording bad habits include:
This is opposite to positive habits - only recording when these bad habits occur. Scenarios for recording bad habits include:
- Recording low-frequency, occasional bad habits
- When successfully cultivated as daily habits, no need for frequent recording, just record exceptions when not done
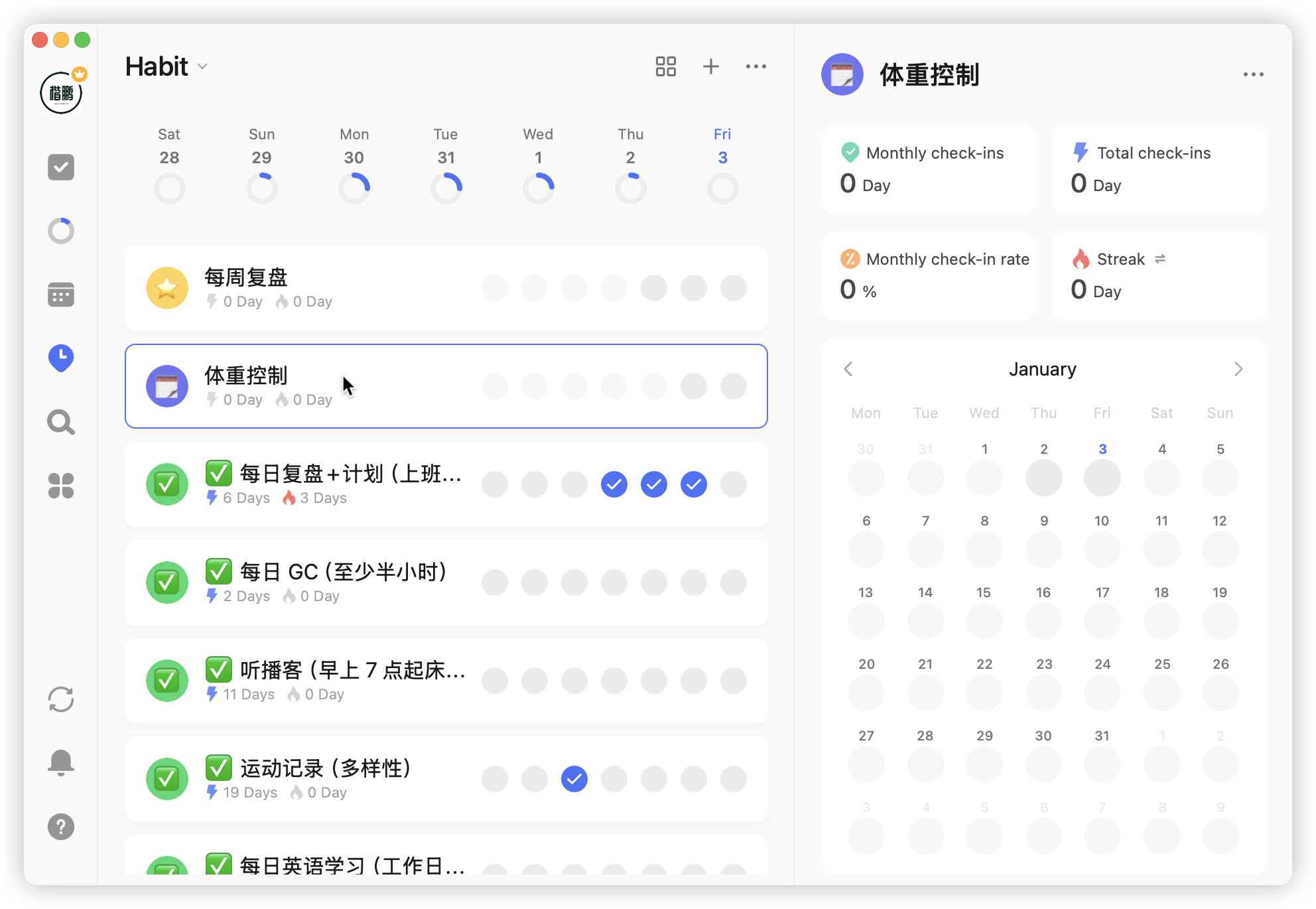
Third is data recording
Habits have built-in calendars, which can be used for data recording. For example, during weight loss, you can record daily weight:
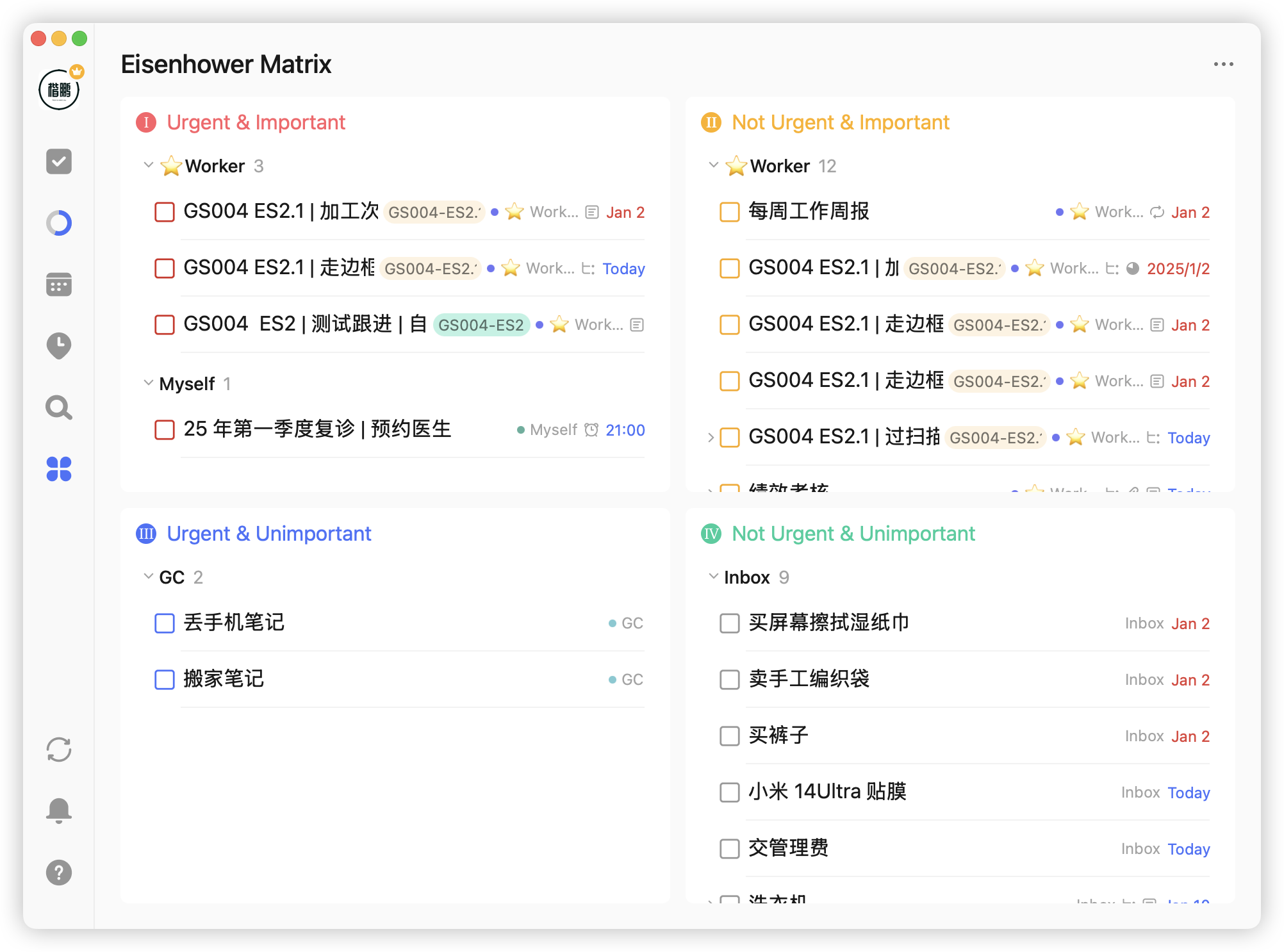
That's my personal use of TickTick over this year. It's indeed excellent software, but undeniably has limitations. For example, the Eisenhower Matrix merely divides tasks by importance and urgency in two dimensions:
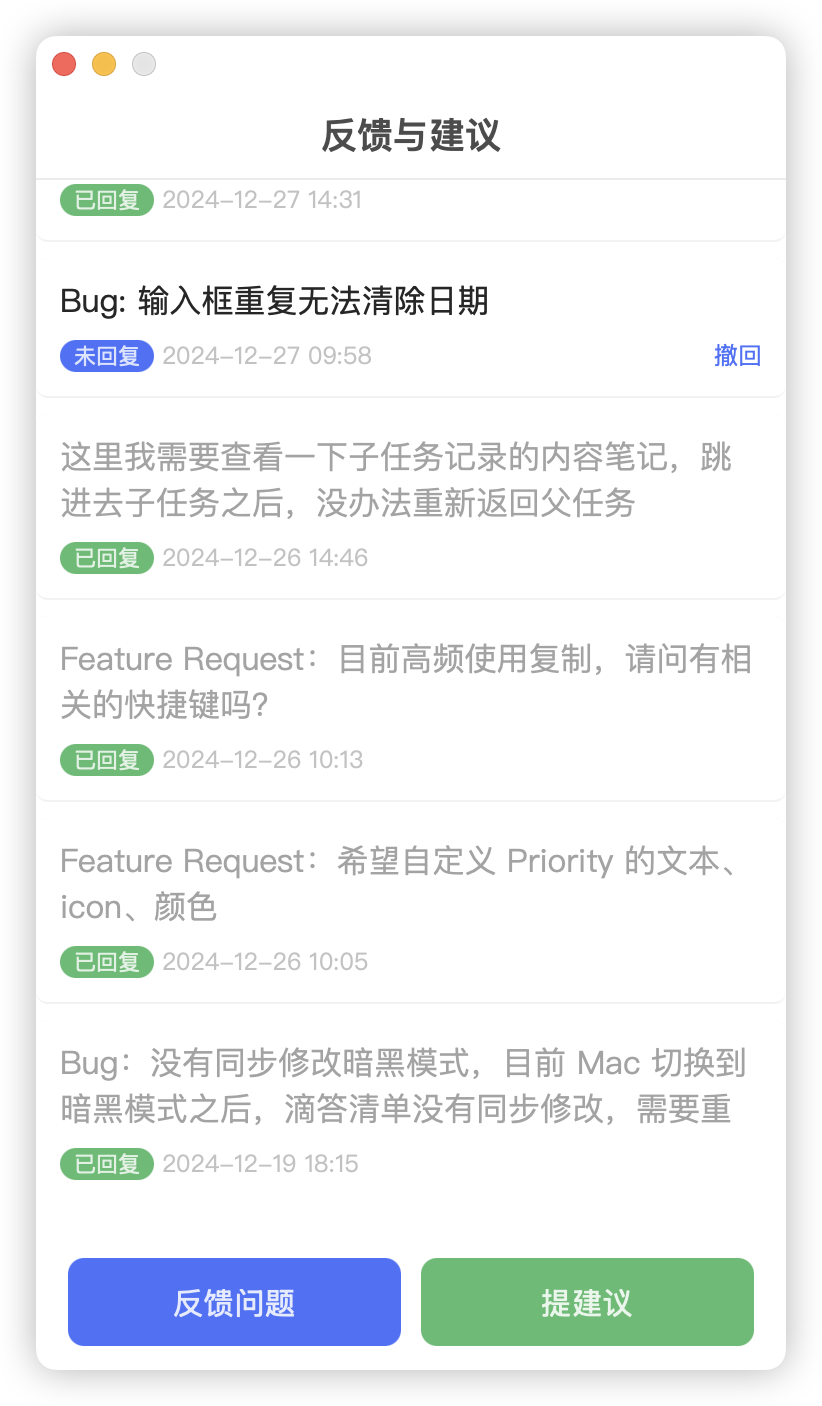
But no software in this world is perfect. When there are problems, solve them. Throughout 2024, I submitted nearly 30 bugs and feature requests to TickTick:
So, does this make me an unofficial tester + product manager? 😆